
Redis 数据类型
Redis 数据类型
所有的数据类型有:String、Hash、List、Set、Zset、BitMap、HyperLogLog、GEO、Stream
String
介绍
String 就是最基本的 Key-Value 类型数据,key 是唯一标识,Value 可以是字符串也可以是数字(整数、浮点数)。
底层是由 SDS(Simple Dynamic String)进行实现。
常用指令
| 指令 | 描述 |
|---|---|
| SET key value | 设置指定 key 的值。如果 key 已经存在,则覆盖旧值。 |
| GET key | 获取指定 key 的值。如果 key 不存在,返回 nil。 |
| GETRANGE key start end | 获取指定 key 中字符串值的子字符串。 |
| SETEX key seconds value | 设置 key 的值,并同时设置过期时间(以秒为单位)。 |
| PSETEX key milliseconds value | 设置 key 的值,并同时设置过期时间(以毫秒为单位)。 |
| SETNX key value | 仅在 key 不存在时设置 key 的值。如果 key 已经存在,则不执行任何操作。 |
| MSET key value [key value …] | 批量设置多个 key-value 对。 |
| MGET key [key …] | 批量获取多个 key 的值。 |
| INCR key | 将存储在 key 上的数字值增 1。 |
| DECR key | 将存储在 key 上的数字值减 1。 |
| INCRBY key increment | 将存储在 key 上的数字值增加指定的 increment。 |
| DECRBY key decrement | 将存储在 key 上的数字值减少指定的 decrement。 |
| APPEND key value | 将 value 追加到 key 原来的值的末尾。 |
| STRLEN key | 获取存储在 key 上的字符串值的长度。 |
应用场景
缓存对象
例如要存储一个uid为1、age=18、name=yukino的对象,可以使用对象类:ID + JSON存储整个对象,也可以使用对象类:ID:属性 + 值的方式存储
1 | # 方式1: |
常规计数
1 | SET blog:1001:likes 0 |
分布式锁
分析:加锁操作可以通过一句SET lock_key unique_value NX PX 10000来实现,这个操作是原子性的。
解锁时,由于需要包含“当前当前客户端持有锁”+“删除这个锁”两个操作,所以要用Lua脚本来实现。
1 | if redis.call("GET",KEYS[1]) == ARGV[1] then |
java代码示例:
1 | import redis.clients.jedis.Jedis; |
共享 Session 信息
如下,在分布式系统中,用户登陆后,登陆会话信息可能存储在服务器1上,但是下一次再来登陆,可能负载均衡算法轮询到服务器2提供服务,这时服务器2上就没有对应的Session信息,出现用户需要重新登陆的情况,而且一份相同的信息需要在不同服务器中存储。
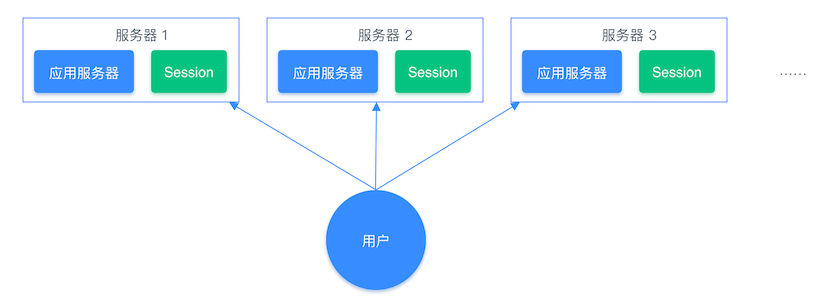
而如果使用Redis来存储管理这些会话信息就十分方便,不会出现重复存储的问题、读取速度快、能够对会话设置过期时间。
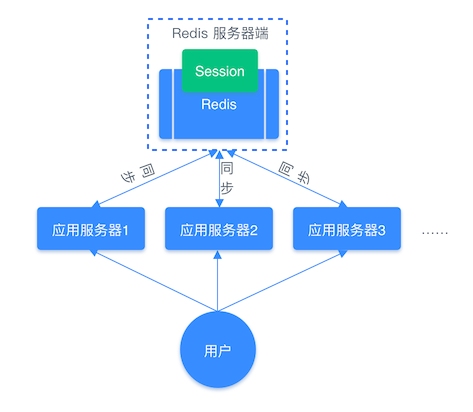
List
介绍
List 是字符串列表,根据按照插入顺序存储和读取,可在头部或尾部快速添加或删除。
底层是由双向链表或压缩列表实现,高版本后由 quicklist 实现。
常用指令
| 指令 | 描述 |
|---|---|
| LPUSH key element [element …] | 将一个或多个值插入到列表的 头部(最左边)。如果 key 不存在,创建一个空列表并执行操作。 |
| RPUSH key element [element …] | 将一个或多个值插入到列表的 尾部(最右边)。如果 key 不存在,创建一个空列表并执行操作。 |
| LPOP key | 移除并返回列表的 头部(最左边)元素。 |
| RPOP key | 移除并返回列表的 尾部(最右边)元素。 |
| BLPOP key [key …] timeout | 阻塞式 LPOP。移除并返回第一个非空列表的头部元素。如果没有元素,则阻塞直到有元素可用或达到 timeout。 |
| BRPOP key [key …] timeout | 阻塞式 RPOP。移除并返回第一个非空列表的尾部元素。如果没有元素,则阻塞直到有元素可用或达到 timeout。 |
| LLEN key | 获取列表的长度。 |
| LRANGE key start stop | 获取列表指定范围内的元素。索引从 0 开始。start 和 stop 可以是负数,表示从尾部开始计数(-1 是最后一个元素)。 |
| LINDEX key index | 通过索引获取列表中的元素。 |
| LSET key index element | 通过索引设置列表中指定位置的元素值。 |
| LINSERT key BEFORE 或 AFTER pivot value | 在列表中指定元素 pivot 的 前面 或 后面 插入新元素 value。 |
| LREM key count value | 根据 count 的值,移除列表中与 value 相等的元素。 |
| RPOPLPUSH source destination | 原子性地将 source 列表的尾部元素弹出,并将其推入 destination 列表的头部。常用于实现循环队列或消息处理。 |
应用场景
消息队列(不完全靠谱)
通过 LPUSH mq message添加消息,通过 RPOP mq读取消息。
消息保序:Redis 的 List 数据类型支持了消息的顺序性。
阻塞读取:但是使用 LPUSH 命令存储消息后,是没有通知的,所以需要一个 while(true) 循环或者间隔一定时间的轮询来消费消息,使用 while(true) 的话会让消费者不断执行RPOP,间隔一定时间轮询的话,做不到及时性。所以另外还有一个命令 BRPOP(Block RPOP)阻塞式右弹出,当消息队列没消息时,会阻塞RPOP命令,有消息进入后才进行RPOP。
重复消息处理:使用全局唯一ID,处理完一条消息后,在消费者程序端记录,若已经处理过则不再处理。
消息的可靠性:List会在一条消息读取后,这条消息就被删除了,如果此时消费者端宕机,重启后这条消息就是没被执行完且无法恢复执行的。为了解决这一问题,可以新增一条备用List,每当一条消息读取后,在备用List中进行存储。
Hash
介绍
Hash 是一个键值对(key-value)集合,其中 value 存储类似于:value = [{field1,value1},{field2,value2},...{fieldN,valueN}],所以 Hash 特别适合存储对象类型数据。
底层是由压缩列表或哈希表实现
常用指令
| 指令 | 描述 |
|---|---|
| HSET key field value [field value …] | 将哈希表 key 中的一个或多个 field-value 对设置进去。如果 key 不存在,将创建一个新的哈希表。 |
| HGET key field | 获取存储在哈希表 key 中指定 field 的值。 |
| HMSET key field value [field value …] | (已弃用,推荐使用 HSET) 批量设置哈希表中的多个 field-value 对。 |
| HMGET key field [field …] | 批量获取哈希表 key 中一个或多个 field 的值。 |
| HGETALL key | 获取哈希表 key 中所有的 field 和 value。 |
| HKEYS key | 获取哈希表 key 中所有域(field)。 |
| HVALS key | 获取哈希表 key 中所有值(value)。 |
| HDEL key field [field …] | 删除哈希表 key 中的一个或多个指定域(field)。 |
| HEXISTS key field | 查看哈希表 key 中指定域 field 是否存在。 |
| HLEN key | 获取哈希表 key 中域(field)的数量。 |
| HINCRBY key field increment | 为哈希表 key 中指定域 field 的整数值增加指定的 increment。 |
| HINCRBYFLOAT key field increment | 为哈希表 key 中指定域 field 的浮点数值增加指定的 increment。 |
| HSETNX key field value | 仅当哈希表 key 中不存在指定域 field 时,才设置该域的值。 |
| HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对,用于处理大规模数据,避免阻塞。 |
应用场景
缓存对象,例如要存储一个uid为1的对象,其age=18,name=yukino
可以如下存储
1 | HSET uid:1 age 18 name yukino |
购物车场景(userId为key、productId为field、productNum为value)(一个购物车里可以有多件商品,不同商品可以选择不同数量)
Set
介绍
Set 是无序唯一键值对集合,支持集合的增删改查,还支持交集、并集、差集操作。
底层是由哈希表或整数集合实现。
常用指令
| 指令 | 描述 |
|---|---|
| SADD key member [member …] | 将一个或多个 member 元素添加到集合 key 中。重复元素将被忽略。 |
| SMEMBERS key | 返回集合 key 中的所有成员。 |
| SISMEMBER key member | 判断 member 元素是否是集合 key 的成员。 |
| SCARD key | 获取集合 key 的成员数量。 |
| SREM key member [member …] | 移除集合 key 中的一个或多个 member 元素。 |
| SPOP key [count] | 随机移除并返回集合中的一个或多个元素。 |
| SRANDMEMBER key [count] | 随机获取集合中的一个或多个元素,但不移除。 |
| SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合。 |
| SINTER key [key …] | 返回给定所有集合的交集(Intersection)成员。 |
| SUNION key [key …] | 返回给定所有集合的并集(Union)成员。 |
| SDIFF key [key …] | 返回第一个集合与后面所有集合的差集(Difference)成员。 |
| SINTERSTORE destination key [key …] | 将给定所有集合的交集存储到 destination 集合中。 |
| SUNIONSTORE destination key [key …] | 将给定所有集合的并集存储到 destination 集合中。 |
| SDIFFSTORE destination key [key …] | 将给定所有集合的差集存储到 destination 集合中。 |
| SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素,用于处理大规模数据,避免阻塞。 |
应用场景
Set的特性在于去重、支持交并补,针对这一特性,可以去发现他的场景:
场景1:点赞/喜欢/收藏场景——因为一个用户不能给同一个文章多次点赞,使用Set可以达到很好的去重效果,当然最大的优势是快速判断“某个用户是否给某篇文章点赞过”。
粗略计算,100万点赞仅需50MB。但是1000万点赞就要500MB,10亿约46.56GB!
所以如果单纯为了统计“计数”,为什么不使用String类型或者HyperLogLog呢?使用Set的目的还是因为能知道每篇文章具体的“点赞用户”
1 | # 用户1对文章1点赞 |
注意
SISMEMBER blog:1 user:1是$O(1)$时间复杂度的,不要弄混淆了……不要和Redis本身是key-value键值对存储类型数据库概念混淆……blog:1只是用于找到这个“value”,这个“value”是Set集合类型的,集合类型查找、判断元素就是$O(1)$(因为底层是(数据量小时)压缩列表或哈希表实现)
场景2:共同关注
就是利用Set支持“交并补”的操作,可以查询两个用户的共同关注,可以用于好友推荐、相关内容推荐,或者像是微信公众号展示“N个朋友关注”
1 | # 用户1关注了1、3、5、7这些公众号(id) |
场景3:抽奖活动
首先每个人肯定是唯一个体,那就把所有人(如果这个基数很大,可以在MySQL查询用户时就做一次“随机抽取”,然后再从这部分已经缩减的数据范围再做抽奖【但是还是要让算法随机】)都放入集合Set。然后要分情况,如果一个人可以多次获奖,那么抽取完后不用SPOP,如果一个人只能中奖1次,就需要SPOP
1 | # 抽出1个特等奖 |
Zset
介绍
Zset,即Sorted Set,有序集合,相比于Set数据类型多一个用于排序的属性score,这个score属性必须是数字类型(支持整数、浮点数、科学计数法)
底层使用压缩列表或者跳表实现。
常用指令
| 指令 | 描述 | ||
|---|---|---|---|
| ZADD key score member [score member …] | 向有序集合 key 中添加一个或多个成员及其分数 (score)。如果成员已存在,则更新其分数。 |
||
| ZRANGE key start stop [WITHSCORES] | 返回有序集合 key 中,索引在 start 和 stop 之间(从小到大排序)的成员。可选择返回分数。 |
||
| ZREVRANGE key start stop [WITHSCORES] | 返回有序集合 key 中,索引在 start 和 stop 之间(从大到小排序)的成员。可选择返回分数。 |
||
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] | 返回分数在 min 和 max 之间(从小到大排序)的成员。 |
||
| ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 返回分数在 max 和 min 之间(从大到小排序)的成员。 |
||
| ZRANGEBYLEX key min max [LIMIT offset count] | (已弃用,推荐使用 ZRANGE) 返回有序集合中,成员的字典序在 min 和 max 之间的元素。要求所有分数相同。 |
||
| ZSCORE key member | 返回有序集合 key 中 member 成员的分数。 |
||
| ZINCRBY key increment member | 为有序集合 key 中 member 成员的分数加上指定的 increment 值。常用于排行榜分数更新。 |
||
| ZCARD key | 获取有序集合 key 的成员数量。 |
||
| ZCOUNT key min max | 统计有序集合 key 中分数在 min 和 max 之间的成员数量。 |
||
| ZRANK key member | 返回有序集合 key 中 member 成员的排名(从小到大排序,从 0 开始)。 |
||
| ZREVRANK key member | 返回有序集合 key 中 member 成员的倒序排名(从大到小排序,从 0 开始)。 |
||
| ZREM key member [member …] | 移除有序集合 key 中的一个或多个成员。 |
||
| ZREMRANGEBYRANK key start stop | 移除有序集合中,指定排名范围内的所有成员。 | ||
| ZREMRANGEBYSCORE key min max | 移除有序集合中,指定分数范围内的所有成员。 | ||
| **ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM\ | MIN\ | MAX]** | 计算多个有序集合的并集,并将结果存储在 destination 集合。 |
| **ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM\ | MIN\ | MAX]** | 计算多个有序集合的交集,并将结果存储在 destination 集合。 |
| ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素,用于处理大规模数据,避免阻塞。 |
应用场景
Zset,即Sorted Set,有序的集合元素,非常适合哪些按照某一规则排序的元素。适合排行榜、最新列表这类需要频繁更新的场景。
场景1:排行榜
设置某个ranking的Zset集合(此处为user:avidbjm:ranking)
1 | # ps:ZADD key score member [score member ...] |
对某一个具体内容进行加分or减分:
1 | # 给user:avidbjm:ranking排行榜中的blog:2增加1分 |
查看排行榜中某个内容的分数值:
1 | # ZSCORE key member |
查看排行榜前三的内容
具体要看怎么定义“排名”,有的排名是score越小越靠前,有的是score越大越靠前,要根据需求来选择使用
ZRANGE key start stop [WITHSCORES]或ZREVRANGE key start stop [WITHSCORES],前者正序,后者逆序Zset是按照score从小到大顺序存储的
1 | # 输出点赞最多的前三名(所以是ZREVRANGE)(WITHSCORES是附带输出score) |
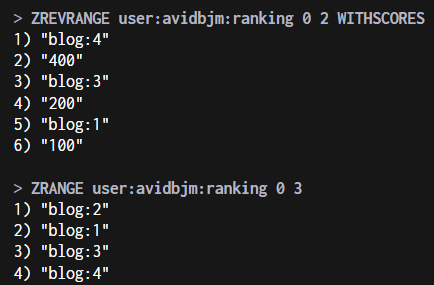
场景2:电话、姓名排序
这个场景的话是因为可以使用ZRANGEBYLEX和ZREVRANGEBYLEX指令来获取某一个特定区间的元素
注意:使用这两个命令时,元素的score必须相同,否则会不准确。
但是
ZRANGEBYLEX命令已经弃用!
电话排序
1 | ZADD phones_by_lex 0 "13912345678" 0 "13800001111" 0 "18698765432" 0 "15011112222" 0 "13900000001" 0 "18800000000" |
姓名排序
1 | ZADD names_by_lex 0 "Adam" 0 "Bob" 0 "Alice" 0 "Bernard" 0 "Charlie" 0 "David" 0 "Brenda" |
BitMap
介绍
BitMap,即位图,是一连串的二进制数组(0、1),因为可以通过位移量(offset)定位元素,所以查询某个元素状态的时间复杂度为$O(1)$。
BitMap 通过将数据元素 ID 直接映射到字节数组的索引($I = \lfloor N / 8 \rfloor$)和字节内位移量($P = N \pmod 8$),实现了极高的查找效率。由于定位一个元素状态仅涉及固定的数组寻址和基础的位运算,其操作时间独立于数据总量,因此时间复杂度为常数时间 $O(1)$,这使其成为处理大规模布尔状态(如用户签到、ID 存在性)的理想数据结构。
常用指令
| 命令 | 描述 | 复杂度 |
|---|---|---|
SETBIT key offset value |
设置 BitMap 中指定偏移量(offset)上的位的值(value,必须是 0 或 1)。如果键不存在,它将自动创建一个足够大的 BitMap。 |
$O(1)$ |
GETBIT key offset |
获取 BitMap 中指定偏移量(offset)上的位的值(0 或 1)。 |
$O(1)$ |
BITCOUNT key [start end] |
统计 BitMap 中设置为 1 的位的数量。可以指定字节范围(start 和 end,均为字节偏移量)。 |
$O(N)$ ( $N$ 是被检查的字节数) |
BITOP operation destkey key [key ...] |
对一个或多个 BitMap 执行位操作(AND, OR, XOR, NOT),并将结果存储到目标键(destkey)中。 |
$O(N)$ ( $N$ 是操作的最长键的长度) |
BITPOS key bit [start end] |
查找 BitMap 中第一个值为 bit (0 或 1) 的位的位置(偏移量)。可以指定字节范围。 |
$O(N)$ ( $N$ 是被检查的字节数) |
STRLEN key |
获取存储在 BitMap 中的字符串值的长度(字节数)。间接反映了 BitMap 的大小。 | $O(1)$ |
GET key |
获取存储 BitMap 的底层字符串值。 | $O(N)$ ( $N$ 是字符串的长度) |
应用场景
BitMap非常适合二值存储的场景(true or false),可以做到用少量内存空间存储大量简单状态信息,例如签到统计、判断用户登陆状态、连续打卡用户数量。
场景1:签到统计
比如需要统计一个用户165天的签到情况,只需要365bit就行,那么存储百万用户一年的登陆情况——$1000000 \times 365 \div 8 \div 1024 \div 1024 \approx 43.5MB$,非常得节省内容。更别说可以设置过期时间进行删除操作。
1 | # 语法:SETBIT key offset value(value只能为0或1) |
场景2:判断用户登陆状态
由于一个用户只有登录、登出两种状态,所以用1位就能记录。那么粗略计算1亿用户大约12MB空间就可以记录。
1 | # uid为10001的用户已登录 |
场景3:连续打卡用户数量
假设要计算连续3天打卡用户:
1 | # 对三天的bitmap进行与操作 |
前面已知,1亿用户的登陆状态也仅需约12MB,那么7天不到100MB,1个月不到500MB。
不过最好设置定时删除的时间,比如每周或每月清空一次,记录到数据库。
HyperLogLog
介绍
HyperLogLog,用于大数计数,提供了一种不完全精确的去重计数,但是可以保证输入元素数量很多时,能保持几乎不变的内存空间。
在 Redis 里,每个 HLL 键的内存开销大约是 12 KB,但是能存储$2^{64}$个不同元素的基数,它的标准误差 (Standard Error) 大约在 0.81% 左右。这意味着它提供的是近似值,而不是精确值。
常用指令
| 命令 | 描述 | 复杂度 |
|---|---|---|
PFADD key element [element ...] |
将一个或多个元素添加到 HyperLogLog 结构中。添加操作仅用于估计集合的基数(不重复元素的数量)。 | $O(1)$ |
PFCOUNT key [key ...] |
返回给定 HyperLogLog 结构的估计基数。可以接受多个键,返回这些 HyperLogLog 并集的估计基数。 | $O(N)$ ( $N$ 是 HyperLogLog 的数量) |
PFMERGE destkey sourcekey [sourcekey ...] |
将一个或多个 HyperLogLog 合并(Merge)到目标 HyperLogLog(destkey)中。目标键将存储所有源键中所有元素的并集的基数估计信息。 |
$O(N)$ ( $N$ 是被合并的 HyperLogLog 的数量) |
应用场景
独立访客 (UV) 统计
统计网站、页面或应用程序在特定时间段内访问的用户数量,这是 HLL 最经典的应用。
1 | PFADD page:uv:20251209 user_id_1 user_id_2 |
多集合并集基数
统计多个相关集合(例如,多个页面的 UV)的总去重基数。
- page:uv:mon: 源键 1,存储周一页面的独立访客(UV)统计数据。
- page:uv:tue: 源键 2,存储周二页面的独立访客(UV)统计数据。
- total:uv:week: 目标键,存储合并后的 HyperLogLog 数据。
1 | PFMERGE total:uv:week page:uv:mon page:uv:tue |
GEO
介绍
Redis GEO (地理空间索引) 命令用于存储、查询和计算地理坐标点(经度/纬度)的数据,底层基于 ZSet 实现。
常用指令
| 命令 | 描述 | 复杂度 |
|---|---|---|
GEOADD key longitude latitude member [longitude latitude member ...] |
将一个或多个地理空间信息(经度、纬度、成员名称)添加到指定的键中。 | $O(\log N)$ ( $N$ 是元素数量) |
GEOPOS key member [member ...] |
从指定的键中获取一个或多个成员的经度和纬度坐标。 | $O(M)$ ( $M$ 是查询的成员数量) |
GEODIST key member1 member2 [unit] |
计算两个成员之间(在存储的键中)的距离。unit 可选:m (米)、km (千米)、ft (英尺)、mi (英里)。 |
$O(1)$ |
GEOHASH key member [member ...] |
返回一个或多个成员对应的 Geohash 字符串。Geohash 是将二维经纬度数据压缩成一维字符串的方法。 | $O(M)$ ( $M$ 是查询的成员数量) |
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASCDESC] |
以给定经纬度为中心,查找指定半径内(radius unit)的所有成员。 |
|
GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASCDESC] |
以给定成员的位置为中心,查找指定半径内(radius unit)的所有其他成员。 |
关于 GEORADIUS 和 GEORADIUSBYMEMBER
$N$:是 GEO 键中存储的总元素数量(地理位置点的总数)。
$C$:是命令实际返回的元素数量(在指定半径范围内的成员数量)。
应用场景
Redis GEO 主要用于处理地理空间位置信息,其核心优势在于能够高效地进行位置存储、距离计算和范围搜索。
| 场景 | 描述 | Redis 命令示例 |
|---|---|---|
| 附近的人/地点搜索 | 查找以用户当前位置为中心,在特定半径范围内的所有兴趣点(POI)或用户。这是 GEO 最常见的应用。 | 添加位置: GEOADD shops 116.3 39.9 "Starbucks" 查询附近: GEORADIUS shops 116.3 39.9 5 km WITHDIST |
| O2O/LBS 服务 | 为外卖、打车或零售服务分配最近的骑手/车辆/门店。例如,查找距离订单地址最近的 3 个外卖骑手。 | 查询附近(按数量限制): GEORADIUS drivers 120.5 30.1 10 km COUNT 3 ASC |
| 距离计算与排序 | 计算两个已知地点或用户之间的直线距离,用于路径规划辅助或收费计算。 | 计算距离: GEODIST places "Shanghai Tower" "Oriental Pearl Tower" km |
| 区域边界判定 | 通过 GEORADIUS 或 GEORADIUSBYMEMBER 确定某个点是否位于特定服务区域或城市半径内。 |
基于成员查询: GEORADIUSBYMEMBER store_locations "MainStore" 50 km |
| 地图点位展示 | 在前端地图上展示大量点位前,可以通过 GEOPOS 快速获取成员的经纬度坐标。 |
获取坐标: GEOPOS users "userA" "userB" |
| Geohash 编码/解码 | 快速获取或存储 Geohash 编码,用于数据传输或数据库索引(尽管 Redis GEO 自动处理了底层编码)。 | 获取 Geohash: GEOHASH places "Eiffel Tower" |
Stream
介绍
Redis Stream 是一个强大的持久化消息队列,支持多消费者组(Consumer Group)和历史消息回溯。
常用指令
| 命令 | 描述 | 复杂度 |
|---|---|---|
XADD key ID field value [field value ...] |
向 Stream 中添加新的消息(条目)。ID 通常使用 * 自动生成,格式为 <millisecondsTime>-<sequenceNumber>。 |
$O(1)$ |
XLEN key |
返回 Stream 中包含的消息(条目)数量。 | $O(1)$ |
XRANGE key start end [COUNT count] |
获取 Stream 中指定 ID 范围内的消息列表。start 和 end 可以是 ID 或特殊字符(如 - 表示最小 ID,+ 表示最大 ID)。 |
$O(N)$ ( $N$ 是返回的消息数量) |
XREVRANGE key end start [COUNT count] |
与 XRANGE 相同,但返回的消息列表是逆序的(从 end 到 start)。 |
$O(N)$ ( $N$ 是返回的消息数量) |
XTRIM key MAXLEN [~] count |
限制 Stream 的最大长度,移除最旧的消息。~ 标志表示近似修剪,以提高效率。 |
$O(1)$ (当消息不多时) |
XGROUP CREATE key groupname ID [MKSTREAM] [ENTRIESREDIS] [LIMIT limit] |
创建消费者组。ID 指定消费者组从哪个 ID 开始消费(通常用 $ 表示从现在开始的新消息,或 0 表示从头开始)。MKSTREAM 可用于在 Stream 不存在时自动创建。 |
$O(1)$ |
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
从 Stream 中读取消息。可以指定读取数量、阻塞时间。可以从多个 Stream 读取,并为每个 Stream 指定起始 ID。 | $O(N)$ ( $N$ 是返回的消息数量) |
XREADGROUP GROUP groupname consumername [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
从消费者组中读取消息。读取未被当前消费者组其他消费者处理的消息。ID 通常为 >,表示读取未传递给当前消费者的下一条消息。 |
$O(N)$ ( $N$ 是返回的消息数量) |
XACK key groupname ID [ID ...] |
确认 (Acknowledge) 指定 ID 的消息已被消费者成功处理。消息将从消费者的未处理消息列表 (PEL) 中移除。 | $O(1)$ |
XPENDING key groupname [IDLE min-idle-time] start end count [consumername] |
获取待处理消息列表 (PEL) 的摘要信息或详细列表。PEL 包含已传递但未被确认的消息。 | $O(log N)$ ( $N$ 是 PEL 中的消息数量) |
XCLAIM key groupname consumername min-idle-time ID [ID ...] |
认领 (Claim) 长期处于待处理状态的消息,将其所有权转给新的消费者。用于处理失败的消费者或死信消息。 | $O(M)$ ( $M$ 是被认领的消息数量) |
XDEL key ID [ID ...] |
从 Stream 中永久删除指定的条目。 | $O(1)$ |
应用场景
| 场景 | 描述 | Redis 命令示例 |
|---|---|---|
| 实时日志收集/处理 | 将应用程序产生的日志(如访问日志、错误日志)实时写入 Stream,供多个后端服务(如分析系统、监控系统)并行消费和处理。 | 生产 (Producer): XADD log:app:* level error message "DB connection failed" 消费 (Consumer Group): XGROUP CREATE log:app monitor $ MKSTREAM XREADGROUP GROUP monitor consumer_A COUNT 10 STREAMS log:app > |
| 异步任务队列 | 用于解耦服务和削峰填谷。例如,用户下单后,将订单 ID 写入 Stream,后续的库存扣减、积分发放、邮件通知等任务由不同的消费者组异步完成。 | 生产: XADD orders:new * orderId 1001 userId 500 消费与确认: XREADGROUP GROUP worker group1 COUNT 1 STREAMS orders:new > XACK orders:new worker 1678881234000-0 |
| 事件溯源 (Event Sourcing) | 存储系统中发生的所有状态变更事件,作为系统的单一事实来源。Stream 的不可变和可回溯特性完美契合事件溯源模型。 | 存储事件: XADD account:123 * type deposit amount 500 历史回溯: XRANGE account:123 0 -1 |
| 消息广播与通知 | 用于将重要通知或配置变更广播给所有订阅者。每个订阅者可以是一个独立的消费者组,确保每个订阅者都能接收到所有消息。 | 生产: XADD configs:update * key "theme" value "dark"多组独立消费: XREADGROUP GROUP service_A consumer_A ... XREADGROUP GROUP service_B consumer_B ... |
| 处理失败与重试 | 当消费者处理消息失败后,消息仍保留在 PEL (Pending Entries List) 中。Stream 提供了认领(CLAIM)机制来处理超时或失败的消息,实现故障恢复和消息重试。 | 查看待处理: XPENDING orders:new worker 0 + 10 认领消息: XCLAIM orders:new worker_new 3600000 1678881234000-0 |
Redis Stream 区别于传统消息队列和 Redis List 的主要优势在于:
- 多消费者组模型: 支持消息的负载均衡(组内消费者抢占)和消息隔离(组间独立消费)。
- 消息可回溯: 消息是持久存储的,可以根据 ID 随时从历史位置开始读取。
- 消息确认 (ACK): 明确的消息确认机制和 PEL 列表确保了消息至少被成功处理一次(At-Least-Once Delivery)。
- 高吞吐量: 底层使用 Radix Tree 和 Listpack 等数据结构,保证了高效的写入和读取性能。






