
MySQL分库分表
MySQL分库分表
总的来说,“分库分表”是用于解决高并发下数据库的连接数不足的性能瓶颈问题、大数据量查询性能瓶颈问题。
实际上分库分表是一种解决数据库性能瓶颈的“最终手段”,非到万不得已不会使用。(在分库分表之前还有索引优化查询、增加查询缓存中间件等手段可以使用)。因为分库分表虽然能解决一部分问题,也会带来新的问题,提高了架构复杂程度,增加维护成本。
分库、分表、分库分表
本质上这是有三种情况——分库不分表、分表不分库、分库又分表。
简而言之,分库是为了解决高并发下连接数不足的问题(因为单库的连接数是有限的);分表是为了解决单表数据量过大(通常数据超过500万条,表大小超过2GB)、查询缓慢的问题。
并发高,就分库;数据量大,就分表。
所以具体要不要分库分表要看算不算符合上述情况。
如何分库
垂直分库
即根据业务边界来分库,例如原先的电商平台将所有数据都存放到一个库中,现在可以分出——订单库、商品库、用户库等
水平分库
将一个库分为多个相同的库,提高系统能承载的并发请求,例如订单库1、订单库2、订单库3。(尤其是双11期间大量订单)
如何分表
垂直分表
将原先一张表中的许多属性分别存到不同表中,比如原先商品表里可能有很多属性,比如价格、商品名称、上架商家、库存数量等。那就可以分成两个表,一个是价格、商品名称这些基础信息存一个表,另外对于不同商家有不同的商品、对应的库存数量这些信息再存一个表。
水平分表
水平分表是分为多个功能相同的小表。
分库分表的算法
范围分片
- 按时间范围分
- 按地域维度分
- 按数据大小分(比如user_id从1-1000一个表、1001-2000一个表……)
hash分片
Sharding Key就是分表的依据。也就是用于分表的那个属性。
简单来说就是对sharding key取模后存储到对应的表中。但是在分表的数量需要动态扩展(集群伸缩)时,简单取模哈希,存在一个问题——原先已经放入表中的数据位置,要大量的重新hash计算后移动。
改进方式:一致性哈希(简单来说一致性哈希的原理就是对$2^{31} -1$取模+虚拟节点 决定放到哪个位置,减少了集群伸缩时数据的大量移动带来的性能消耗)(关键词:环形、增加虚拟节点、顺时针距离最近)
查表分片
就是多增一个表,要查询数据前,先查询这个表来判断所需数据在那个表。但是需要注意的是,这个新增的表数据量不能太大,否则本身也会成为性能瓶颈。(毕竟是多查了张表)
分库分表架构模式
客户端模式
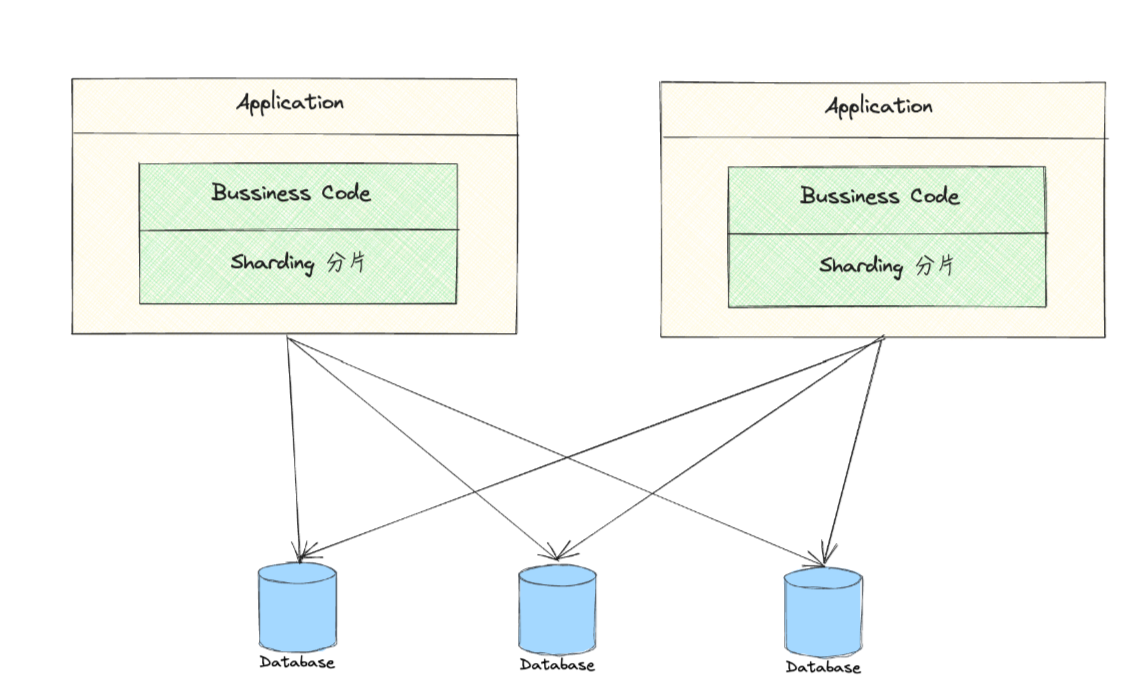
业务代码有侵入。
java开发中通过提供jar方式实现,例如ShardingSphere-JDBC,美团的Zebra、MTDDL,阿里的TDDL
代理模式
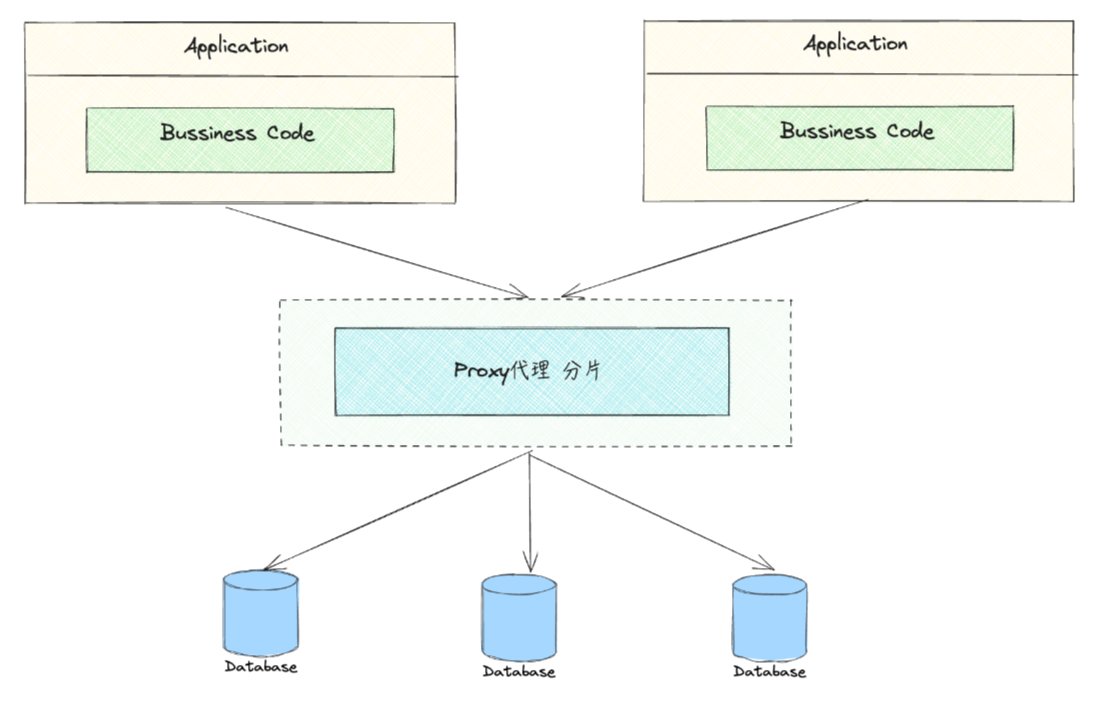
业务代码无侵入,对业务方透明。
例如ShardingSphere-Proxy,阿里的MyCat,美团的Meituan Atlas,百度的Heisenberg。






