
MySQL事务
MySQL事务
事务,学名transaction。直译应该叫做“交易”。交易场景如下,A向B去买了一件商品,具体过程如下:
- A从自己的钱包拿出100元
- B的钱包获得了100元
- B将商品从自己的摊位拿出
- A拿到了商品
交易结束。上述的4个步骤是一整个过程,要么全部成功,要么全部失败,不能再任何一个地方中断。所以有了事务的四大特征:
ACID
A:原子性(Atomicity),即一个事务内包含的所有事件要么全部执行成功,要么因为一个出错就全部失败。
C:一致性(Consistency),即要保证数据之间的互相约束要始终有效。(有点抽象)典型例子就是转账,原本两人钱总和是1000,那么无论怎么转账,和都是1000。
I:隔离性(Isolation),即事务之间相互隔离,不能相互影响。
D:持久性(Durability),事务提交后,数据就是永久保存的,不应该丢失。
InnoDB引擎通过什么技术来保证事务的ACID呢?
持久性通过redo log日志(重做日志)来保证
原子性通过undo log日志(回滚日志)来保证
隔离性通过MVCC或锁机制来保证
一致性通过持久性、原子性、隔离性来保证。
4种常见并发问题
这四种现象均是并发情况下产生的问题,或多或少违背了事务应有的性质。
严重程度从大到小为:脏写 > 脏读 > 不可重复读 > 幻读。(后三个是重点)
脏写(Dirty Write)
实际InnoDB由于行锁的存在,下面两个事务只是正常的并发写入过程而已(彼此互斥),不能说是脏写。此处只是作为例子说明脏写。(为了知识的完整性)(实际更重要的还是脏读、不可重复读、幻读这三个)
InnoDB存储引擎下
脏写:一个事务修改了另一个未提交事务修改过的数据。
| 时间 | 事务A | 事务B |
|---|---|---|
| 1 | 启动事务A | |
| 2 | 启动事务B | |
| 3 | update user set money = 200 where id = 1 | |
| 4 | update user set money = 100 where id = 1 | |
| 5 | 提交事务A | |
| 6 | 回滚事务B |
上面事务A修改了另一个事务B中未提交的这条记录(同样id=1),后来事务B回滚了,虽然事务A已经提交,但是最后回滚完发现自己什么都没改。
脏读(Dirty Read)
| 时间 | 事务A | 事务B |
|---|---|---|
| 1 | 启动事务A | |
| 2 | 查询余额为100 | |
| 3 | 启动事务B | |
| 4 | 查询余额为100 | |
| 5 | 修改余额为200 | |
| 6 | 查询得到余额val1 | |
| 7 | 提交事务B | |
| 8 | 查询得到余额val2 | |
| 9 | 提交事务A | |
| 10 | 查询得到余额val3 |
脏读:一个事务读到了另一个未提交事务修改过的数据。
- val1 = 200,val2 = 200,val3 = 200。
- 因为是脏读。
不可重复读(Non-Repeatable Read)
| 时间 | 事务A | 事务B |
|---|---|---|
| 1 | 启动事务A | |
| 2 | 查询余额为100 | |
| 3 | 启动事务B | |
| 4 | 查询余额为100 | |
| 5 | 修改余额为200 | |
| 6 | 查询得到余额val1 | |
| 7 | 提交事务B | |
| 8 | 查询得到余额val2 | |
| 9 | 提交事务A | |
| 10 | 查询得到余额val3 |
不可重复读:一个事务能读取到另一个已提交事务修改后的数据,从自己事务来看就是前后读取到的值不一致。
- val1 = 100,val2 = 200,val3 = 200。
- val1读不到事务B修改后的,但是事务B修改后能读取到(所以val2 = 200)
幻读(Phantom)
幻读:事务A先根据某些条件查询出一些记录,之后事务B又向表内插入或删除了满足事务A条件的记录,然后事务A能读取到事务B新加入(或删除)的记录。
| 时间 | 事务A | 事务B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT COUNT(*) from user WHERE money > 100;(查询结果为5) | |
| 3 | BEGIN; | |
| 4 | INSERT INTO user VALUES(6,”yukino”,150); | |
| 5 | COMMIT; | |
| 6 | SELECT COUNT(*) from user WHERE money > 100;(查询结果为6) | |
| 7 | COMMIT; |
时间点6发生了幻读。
4种MySQL隔离级别
为了解决并发过程中可能产生的问题,设计InnoDB的佬想了四种隔离级别。
- 读未提交(READ UNCOMMITTED):最低的隔离级别,能读取到另一个未提交事务中的修改后的数据。
- 读已提交(READ COMMITTED):一个事务能读取到另一个事务提交修改后的数据。
- 可重复读(REPEATABLE READ):一个事务内读取到的数据始终一致。
- 串行化(SERIALIZABLE):最高的隔离级别,一个事务完成才能进行下一个事务。
不同隔离级别下可能发生的问题:
| 隔离级别 | 可能发生的问题 |
|---|---|
| 读未提交 | 脏读、不可重复读、幻读 |
| 读已提交 | 不可重复读、幻读 |
| 可重复读 | 幻读 |
| 串行化 | / |
实际上,MySQL的InnoDB引擎在在可重复读的隔离级别下,已经能避免大部分的幻读问题了。
但是并不绝对:blog
MVCC
要解释MVCC的工作原理,要先理解两个概念——版本链、Read View。
版本链
此处借用《MySQL是怎样运行的:从根上理解MySQL》的两张图。
官方/准确术语: History List (历史列表) 或通过 Roll Pointer (回滚指针) 链接的记录版本。
版本链的作用就是通过 Undo Log 组织数据的所有历史版本,提供多版本数据源。
至于有什么作用?是为了实现读未提交、读已提交、可重复读不同隔离级别所需要的数据结构(借用下算法里“数据结构”的概念)。
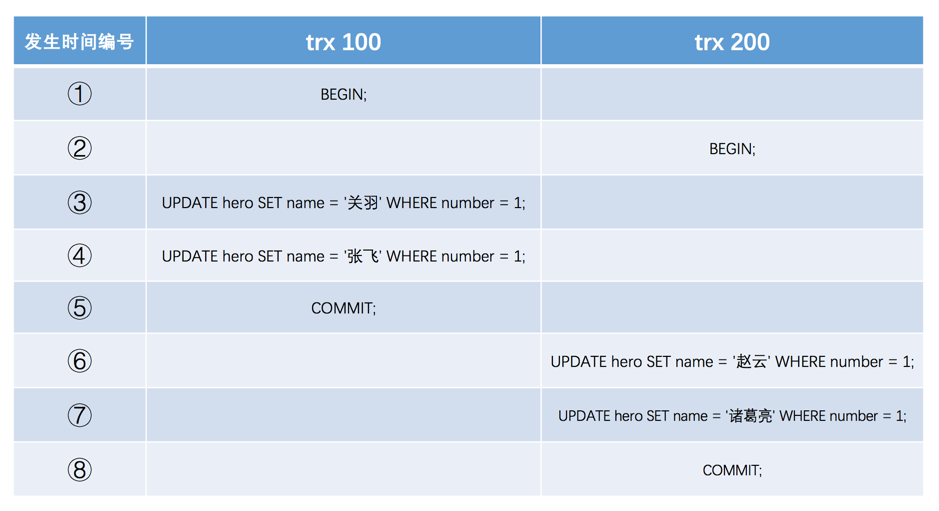
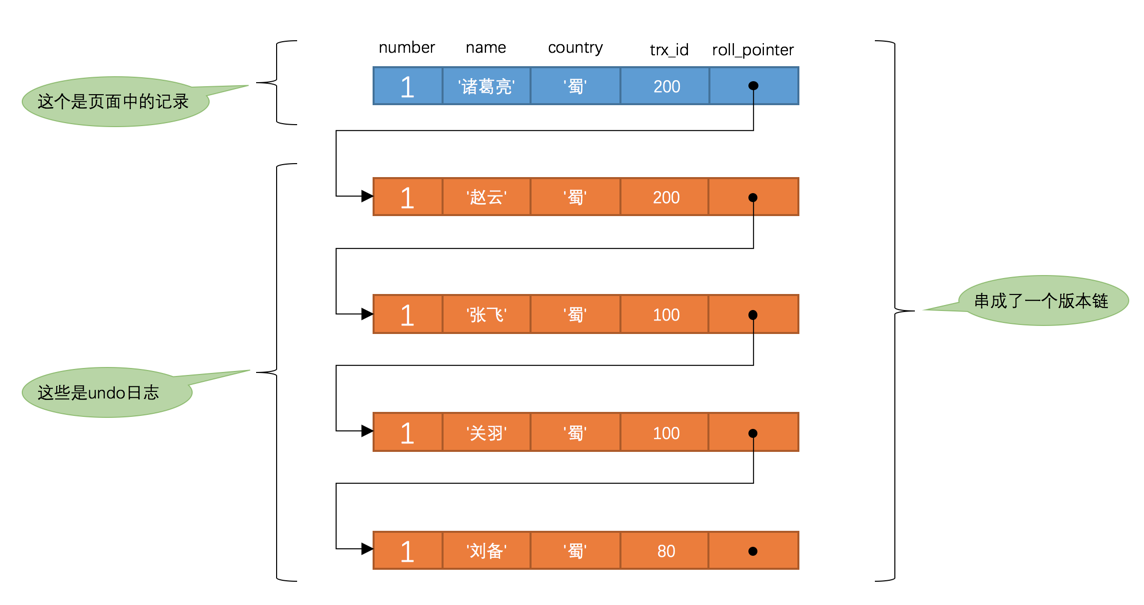
Read View
此处借用事务隔离级别是怎么实现的? | 小林coding 中的图。
官方/准确术语: Consistent Read View(一致性读视图) 或 Snapshot (快照)。
Read View作用就是决定当前事务能看到哪个数据版本(可见性判断)。
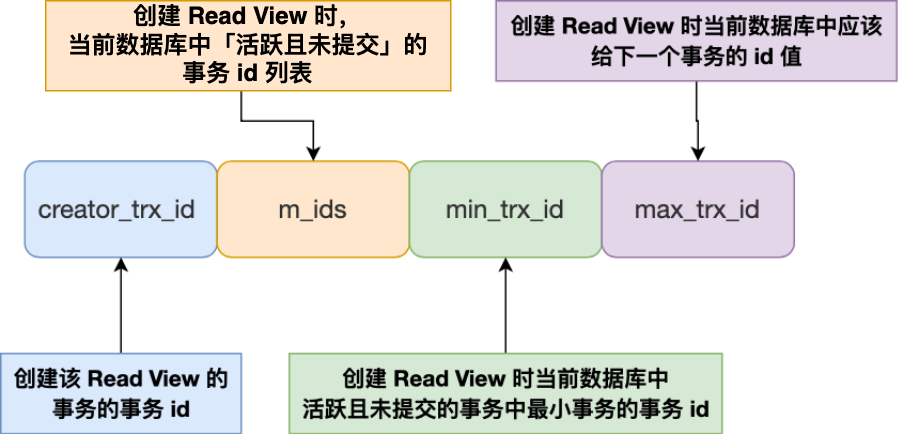
详细介绍见上面两篇博客(死记硬背具体如何比较的没必要……)
大概理解就是——通过当前看一下记录中隐藏列中的trx_id:
trx_id等于creator_trx_id?说明是当前事务版本,那么就可以看到。trx_id小于min_trx_id?说明生成该版本数据的事务的提交早于当前事务生成Read View。trx_id大于max_trx_id?说明生成该版本数据的事务的开启晚于当前事务生成Read View。trx_id在min_trx_id和max_trx_id之间?如果
trx_id在m_ids中,说明生成该版本数据的事务活跃且未提交。如果
trx_id不在m_ids中,说明生成该版本数据的事务已提交。如果
trx_id不在m_ids,它只能表示该事务在Read View生成的那一刻就已经提交了(或已经回滚,但回滚后的版本最终指向前一个已提交的版本)。
如果一个版本不可见,就沿着版本链看看下一个是否可见。
大致理解,但不准确……
因此不同隔离级别,只是可见性的不同。比如读未提交,就是能看见trx_id在m_ids的版本数据。又如读已提交,必须是trx_id不在m_ids中才能看见。又如可重复读,trx_id必须小于min_trx_id才可见。
MVCC在不同隔离级别下的使用情况
准确描述如下:
读未提交 (READ UNCOMMITTED)
| 描述 | 最大异常 | InnoDB 实现 | 可见性机制 |
| —————————————————————————————— | ———————————————————————— | —————————————————————————————— | —————————————————— |
| 描述: 一个事务可以读取到其他事务尚未提交(未持久化)的修改。 | 脏读 (Dirty Read): 允许读取到未提交的数据。 | InnoDB 不使用 MVCC 进行读取,直接读取数据的最新物理版本。 | 不使用 Read View,总是读取最新数据。 |读已提交 (READ COMMITTED)
| 描述 | 最大异常 | InnoDB 实现 | 可见性机制 |
| ————————————————————————————- | —————————————————————————————— | —————————————————————————————— | —————————————————— |
| 描述: 一个事务只能读取到其他事务已经提交的修改。 | 不可重复读 (Non-repeatable Read): 同一事务内,两次读取同一行记录,可能会得到不同的值。 | InnoDB 不使用 MVCC 进行读取,直接读取数据的最新物理版本。 | 不使用 Read View,总是读取最新数据。 |可重复读 (REPEATABLE READ)
| 描述 | 最大异常 | InnoDB 实现 | 可见性机制 |
| —————————————————————————————— | —————————————————————————————— | —————————————————————————————— | —————————————————————————————— |
| 描述: 保证在同一事务内,对同一数据的多次读取结果是一致的。 | 幻读 (Phantom Read): 在大部分情况下,MySQL 的REPEATABLE READ级别会通过特殊的锁机制阻止幻读。 | 事务第一次执行SELECT语句时生成 Read View,并在整个事务生命周期内重复使用该视图。 | 由于 Read View 始终不变,事务只能看到在视图生成前就已提交的数据版本,从而实现了可重复读。此外,通过 Next-Key Locks(临键锁) 解决了幻读问题。 |串行化 (SERIALIZABLE)
| 描述 | 最大异常 | InnoDB 实现 | 可见性机制 |
| —————————————————————————————— | ————————————————————————————- | —————————————————————————————— | ————————————————- |
| 描述: 最高的隔离级别。所有事务按顺序执行,彼此完全隔离,如同单线程运行。 | 无异常。 杜绝所有并发异常(脏读、不可重复读、幻读)。 | 所有普通SELECT语句都会隐式地转换为SELECT ... FOR SHARE,对读取的行加共享锁(S 锁),阻止其他事务的写入。 | 主要依赖悲观锁,而不是 MVCC。 |







