
MySQL索引
MySQL索引
索引的优势与劣势
简而言之,优势——能大大加快数据的查询速度。劣势——增加了额外的空间来存储索引,且执行插入、删除操作语句时增加了维护索引的成本。
所以建立了索引就一定是要用起来的,不然不如不建立,而且索引对于优化查询的效果是否大,和我们如何写索引(使用哪种索引?存储引擎?),如何写SQL语句,以及数据(数据量、数据类型、数据分布等)有很大关系。
不过总体来说使用索引的优势还是大于不使用。
索引的类型分类
按数据结构分:
可以分为B+Tree索引、哈希索引、Full-Text索引,一般使用的都是B+Tree索引。
按物理存储分:
分为聚簇索引(也称主键索引)和非聚簇索引(或称二级索引、辅助索引),说聚簇索引,那就是在说InnoDB存储引擎了,InnoDB存储引擎在存储数据时,会使用主键索引的方式,将索引和数据放在一起,数据是按照主键进行有序存储的。二级索引是另外一个空间中,存储了id(主键)和索引字段。
就想象有两棵B+树,一棵的叶子节点上存储了所有字段数据,且按照id排序;另一棵的叶子节点上存储的是id和索引字段,且按照索引字段排序。
按字段特性分:
分为主键索引、唯一索引、前缀索引、普通索引。这个见名知义了。主键索引就是以主键为索引(非空且唯一);唯一索引就是索引字段唯一;前缀索引指的是利用varchar、char等类型的前几个字符建立的索引;普通索引就是一般的索引(字段可以为null、也可以不唯一)
按字段个数分:单列索引、联合索引。比如对(score)字段建立索引,也可以是对(score,name)两个字段建立联合索引。
如何用好索引
众锁周知,索引是把双刃剑,既带来了查询性能的提升,又带来了维护索引的开销。因此我们要结合具体的场景来分析是否要用索引,也要知道什么样的场景索引会生效、什么场景索引会失效。
适合使用索引的场景
- 在
where、order by中频繁使用到的字段 - 索引字段区分度较高
- 在进行多表查询时,对外键增加索引可以大大提高join操作效率
- 建立索引的字段不应过长、如果太长可以考虑使用前缀索引
- 建立联合索引时,应遵循最左匹配原则,把使用频率最高的放在最左边
- 尽量使用联合索引代替单列索引
不适合使用索引的场景
- 字段不在
where、order by中使用 - 字段区分度低(比如性别)
- 经常删改的字段不适合建立索引
- 索引不能参与计算,会导致索引失效,所以经常要参与计算的字段不应建立索引
- 索引字段无序时不建议建立索引,会导致页分裂
索引失效场景
查询带有or,且其中一个条件的字段没用到索引
使用了联合索引,但是sql查询时没有最左匹配
模糊查询(like)字符以%开头
索引字段参与计算
索引字段使用函数计算
隐式类型转换导致索引失效,比如数据库中phone是varchar类型,然后where条件写了个整数类型。相当于对字段使用了
CAST类型装换函数,所以索引失效(MySQL在比较字符和数字时,是将字符转换为数字)不同字段值对比导致索引失效(?)
反向操作,比如写NOT IN、IS NOT NULL、!=之类的。
其他知识点
可以使得知识体系更完善。(当然硬要说还可以说存储引擎——InnoDB、MyISAM)
索引覆盖
索引覆盖,就是要查询的列,在索引中已经包含,则被所使用的的索引覆盖,不需要再回表。
假设有一个联合索引为idx(a,b,c),where过滤条件符合最左匹配原则,且select查询时只查询了a和b两个字段,那么直接在二级索引表中查出数据返回,不用去得到id值、然后再进行回表,在主键索引中查找对应数据。
所以如果只要查询a、b、c三个字段信息的话,就不要写select *,避免不必要的回表操作。
最左匹配原则
指的是,使用索引时,存在最左匹配的规则。
假设有一个联合索引idx(a,b,c)
- where过滤条件必须先有a、再有b、再有c。由于order by优先级比where低——所以假设where条件中是b,order by中是a,那么这个idx不生效。
- 当a是严格大于(>)或严格小于(<)时,那么后面的b、c都不生效。但是如果a是≥或≤,则b、c照样生效。
注:由于优化器的存在,where中字段的顺序不影响最左匹配(即where a = ? and b = ?等价于 where b = ? and a = ?)
索引下推
索引下推,就是将Server层筛选数据的工作,放到了执行引擎层来做。
这个机制是MySQL 5.6新增的优化机制,默认开启。
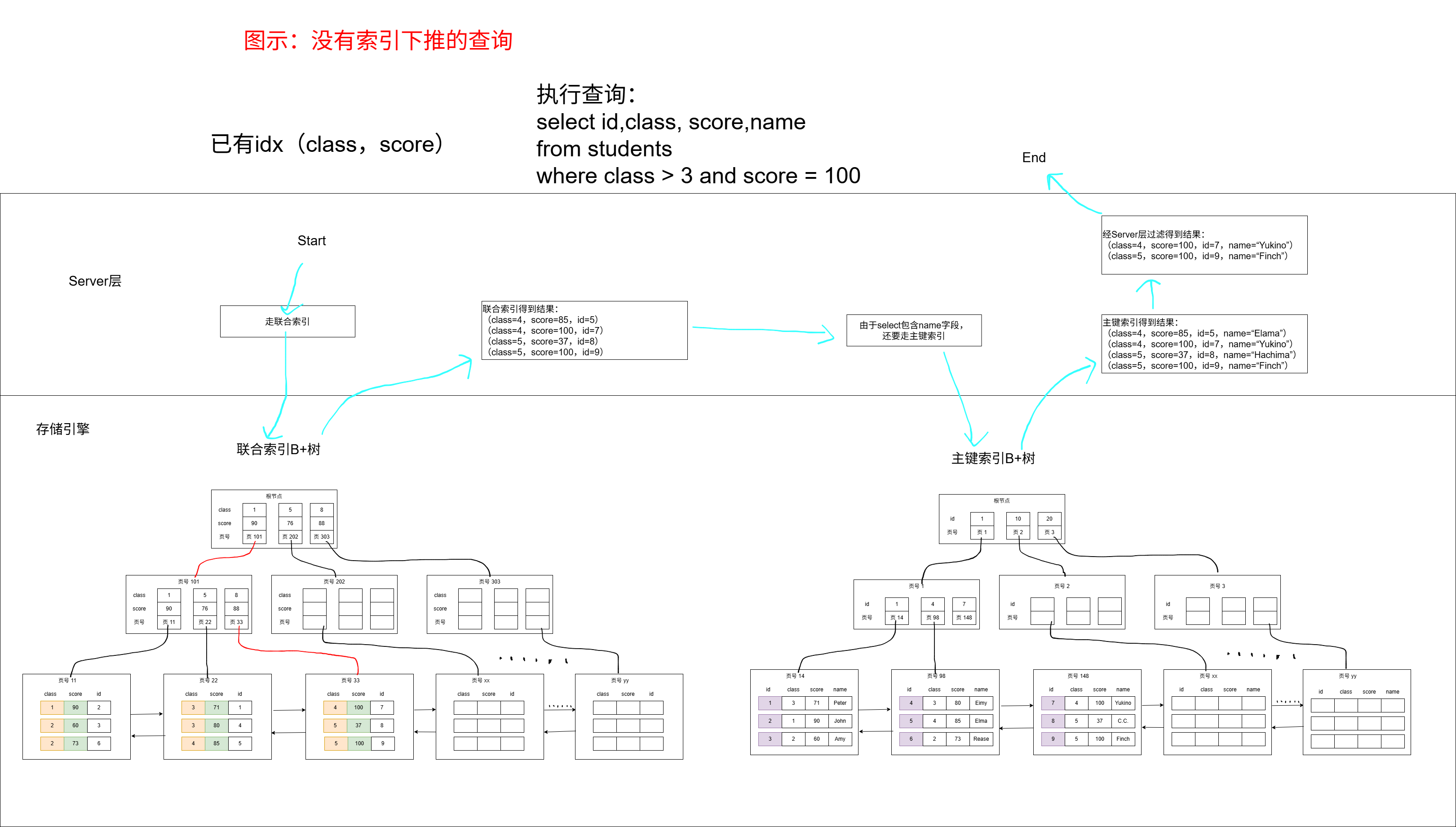
无索引下推时的查询:
有索引下推时的查询:
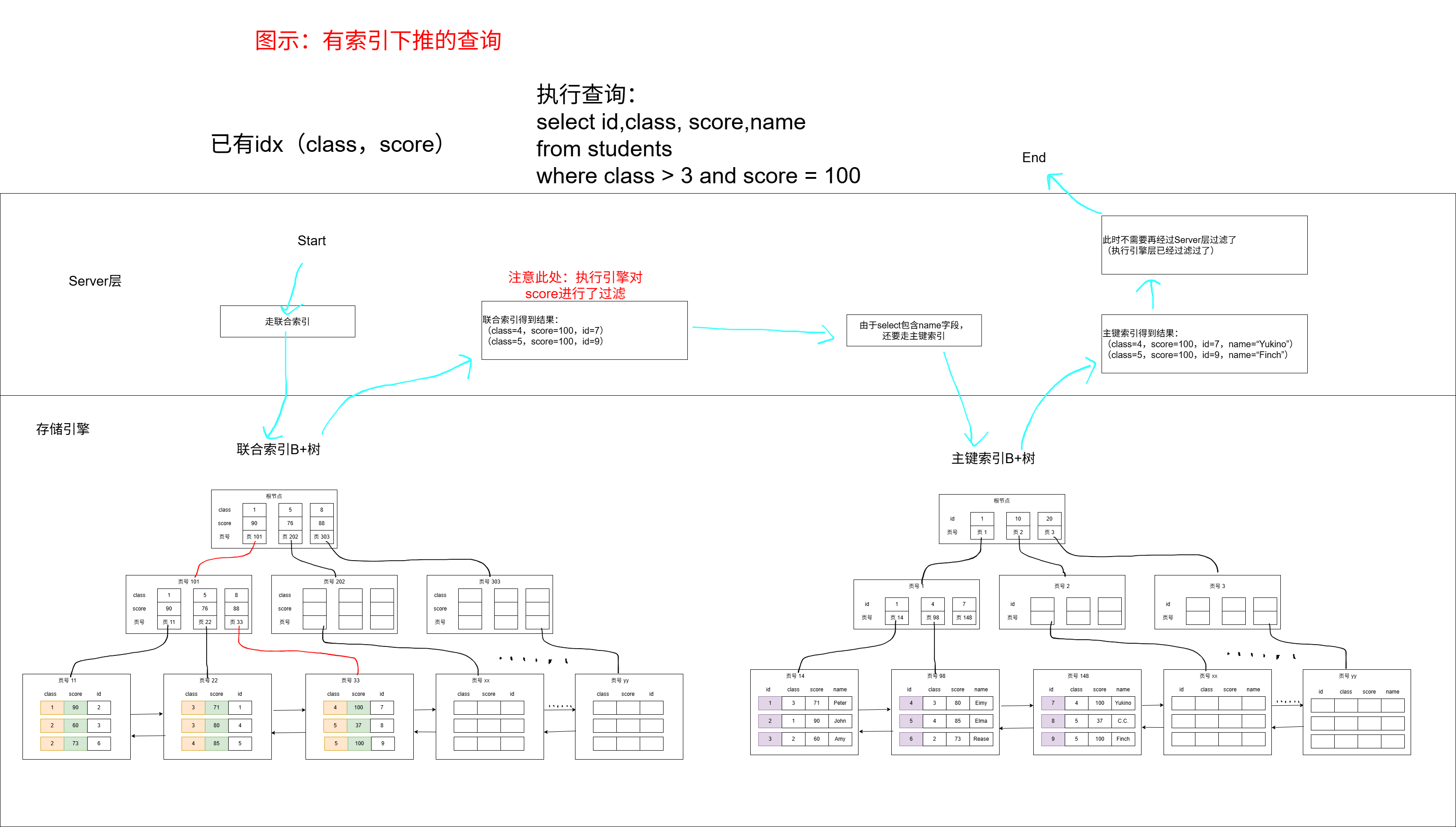
可以发现,有索引下推后,回表的次数就变少了。(原先需要对4条数据通过id进行回表查询、而现在只有两条数据需要回表查询)。
CBO:基于成本的优化器
CBO,即Cost-based-Optimizer,基于成本的优化器,会通过计算一条sql语句的使用索引的成本的来决定是否使用or使用哪条索引。
该部分参考自技术文章摘录——索引出错:请理解CBO的工作原理
两个“奇怪”的案例:
案例1:明明两次查询时的SQL语句均相同,为什么一次使用了索引,一次没有使用索引?
通常是因为优化器认为使用索引的cost(成本)高于全表扫描。比如一条范围查询语句,但是满足条件的记录数很多,近乎与全表数据了,此时即使可以走索引,但是还要再全部回表,执行成本就很高。(不如直接全表扫描)
案例2:索引建立在有限状态的字段上
假设有一张订单表,我们对于其状态建立了索引,而状态可能有未完成、进行中、已完成这几类。通常订单状态大部分是已完成的,而未完成和进行中相比是少量的,这就存在数据倾斜,而优化器却认为订单状态是平均分布的,导致对于未完成和进行中的订单,优化器认为记录数很多,基于索引方式+回表查询成本太高。解决方案是,让优化器能知道数据的分布,可以利用MySQL 8.0的直方图功能,创建一个直方图,使其知道数据分布,从而更好地选择执行计划。
实践
联合索引(a,b,c),下面的查询语句会不会走索引?如果走,具体是哪些字段能走?
select * from t_test where a = 1 and b = 2 and c = 3;select * from t_test where a = 1 and b > 2 and c = 3;select * from t_test where a = 1 and b >=2 and c = 3;select * from t_test where c = 1 and a = 2 and b = 3;select * from t_test where a = 2 and c = 3;select * from t_test where b = 2 and c = 3;select a,b from t_test where a = 1 and b > 2;
解答:
- 遵循最左匹配原则,abc都能走索引,查询方式是在联合索引找到主键后,回主键索引查找完整数据。
- 根据最左匹配原则,ab可以走,c无法走,但是c可以索引下推(MySQL 5.6优化)
- abc都可以走,此处
b>=2也是可以走索引的,且不会破坏c - abc都能走,where查询条件字段的顺序不会影响,MySQL优化器会帮我们调整字段的查询顺序。
- a能,c不能走索引,但是c能索引下推。
- bc都不能,但是bc能走索引下推
- ab都能走索引,且查询方式是索引覆盖(不用回表)
where a > 1 and b = 2 and c < 3怎么建立索引?
- 如果是idx_ab、idx_ac、idx_abc、idx_acb,则abc都不走索引
- 如果是idx_ca、idx_cb、idx_cab、idx_cba,则abc都不走索引
- 如果是idx_ba,则b和a走索引。
- 如果是idx_ca,则b和c走索引。
- 如果是idx_bac,则b和a走索引,c不走索引但走索引下推。
- 如果是idx_cab,则b和c走索引,b不走索引但走索引下推。
where a > 100 and b = 100 and c = 123 order by d怎么建立联合索引?
推荐idx_bcda或者使用idx_cbda,这样的话bcd都能走索引(不会发生filesort),而a能走索引下推。
如果把a和d的位置互换,比如idx_bcad,虽然bca能走索引,但是在order by中的d就走不了索引(会发生file sort)。
select * from t where a > ? and b = ? or c = ?怎么优化?
分析:如果有or,那么光是索引idx_ba还是会导致索引失效。
所以应该使用索引idx_ba和idx_c,这样索引不会失效。
联合索引(a,b,c),
select * from t where a = ? and b in (?,?) and c = ?会不会走索引?如果走,具体是哪些字段能走?
如果是in (?,?),并没有绝对的答案说走不走索引,如果b的值有3个(1、2、3),如果b = 1或b = 2的个数很少,那么b in (1,2)是会走索引的,但是如果b = 1或b = 2的个数很多(几百万条),那么b not in (1,2)就不会走索引(节省回表开销)。






