
Python爬虫基础
Python爬虫基础
爬虫,就是通过一个程序,根据url进行爬取网页,获取有用信息。
爬虫的核心在于:
- 根据需求,确定要爬取的url
- 模拟浏览器进行访问,获取到返回的HTML源码
- 对该HTML进行解析,获取需要的数据
爬虫的难点在于——如何应对反爬手段。
本文聚焦与两方面内容:
- 一些基本爬虫工具库的使用(urllib、xpath、jsonpath、bs4、request)
- 进行爬虫过程中遇到的一些问题以及解决方案
urllib
官方文档:其中urllib.request库用于打开和读取URL、urllib.parse用于解析URL,此两库常用。
urllib 菜鸟教程:简单使用、查常用的API
- [ ] 补充一些使用demo,放github仓库
XPath
lxml.etree库-博客园:API
XPath 菜鸟教程:重点关注XPath语法
- [ ] 补充一些使用demo,放github仓库
jsonpath
- [ ] 补充一些使用demo,放github仓库
bs4
- [ ] 补充一些使用demo,放github仓库
requests
- [ ] 补充一些使用demo,放github仓库
Selenium
菜鸟教程:里面的方法名已经过时(在高版本被移除),通过传入一个By.[ID等可选]参数来解决
- [ ] 补充一些使用demo,放github仓库
问题以及解决方案
1. 根据url已获取到HTML,但没解析出内容?
具体场景为:使用urllib.request定制Request对象、模拟浏览器发送请求后,成功获取到HTML源码
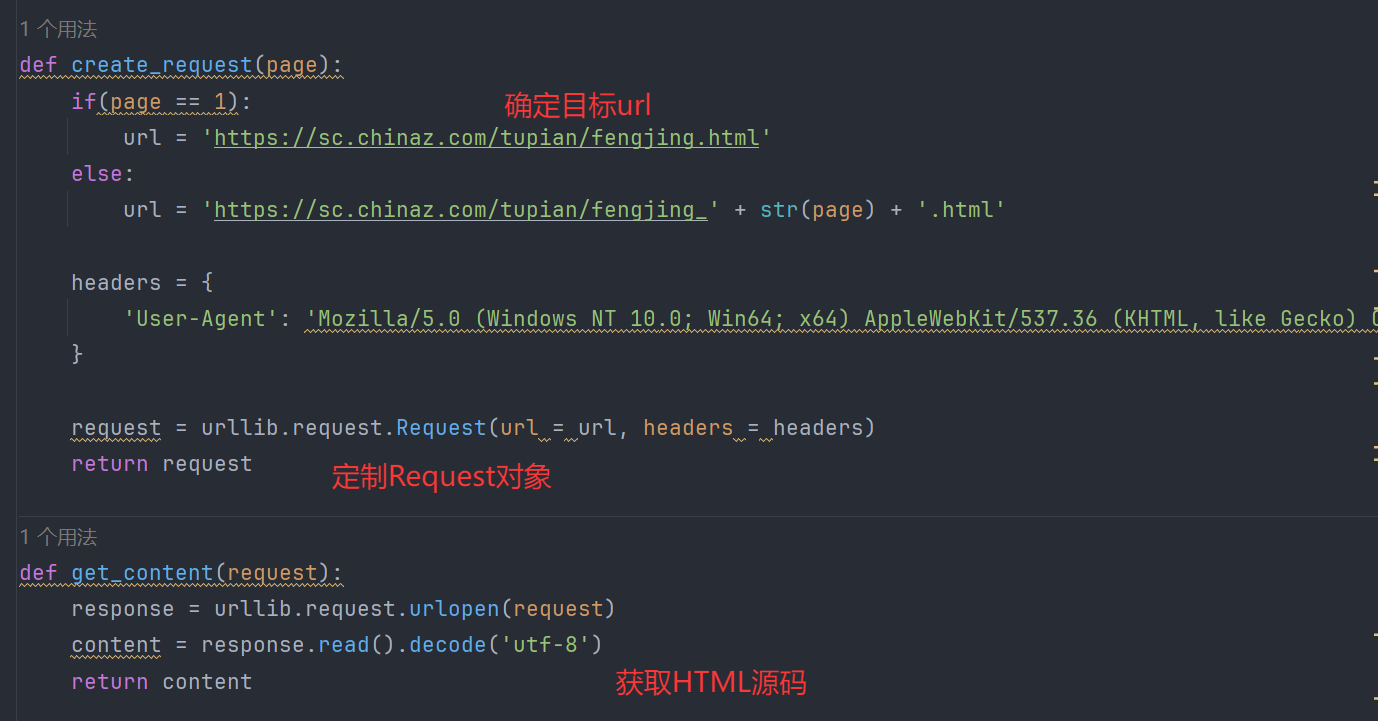
而在进行xpath解析时,却出了问题,先在网页HTML源码中寻找资源路径、且通过xpath插件验证过可行
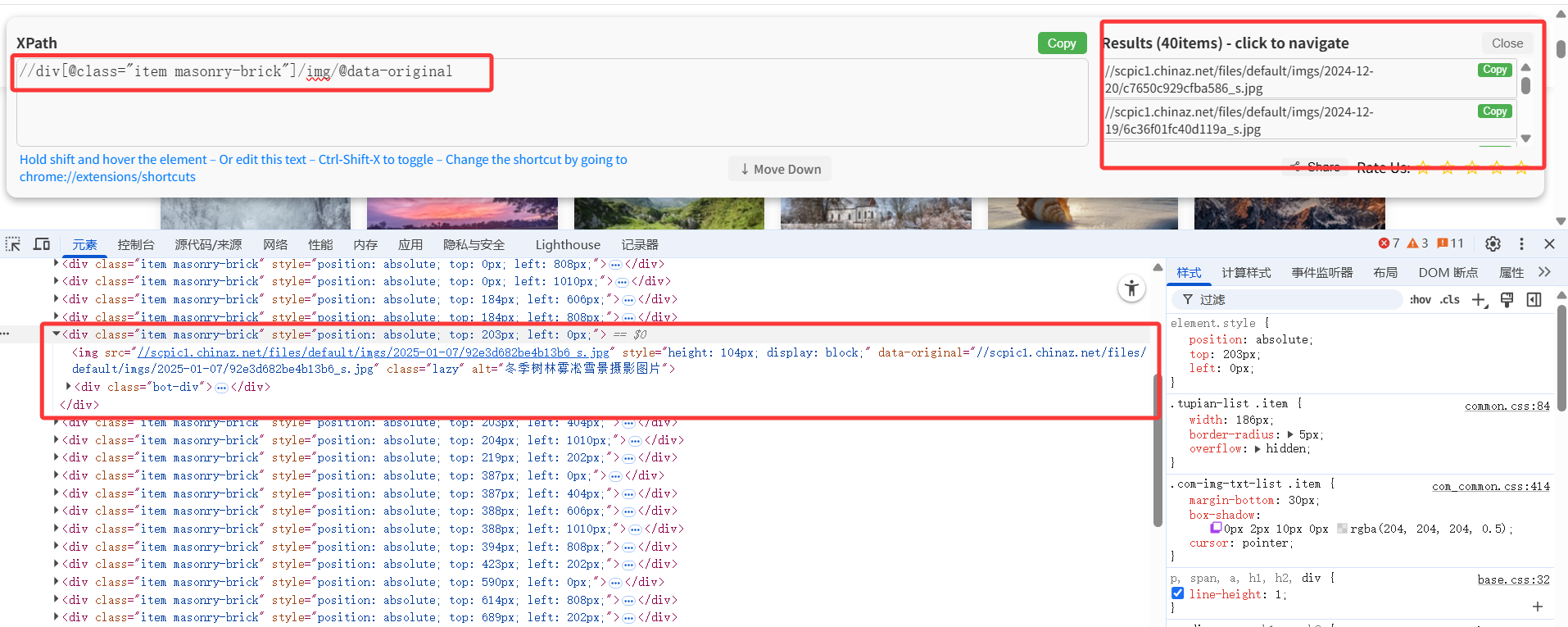
调试发现:无法通过该xpath表达式获取到对应内容
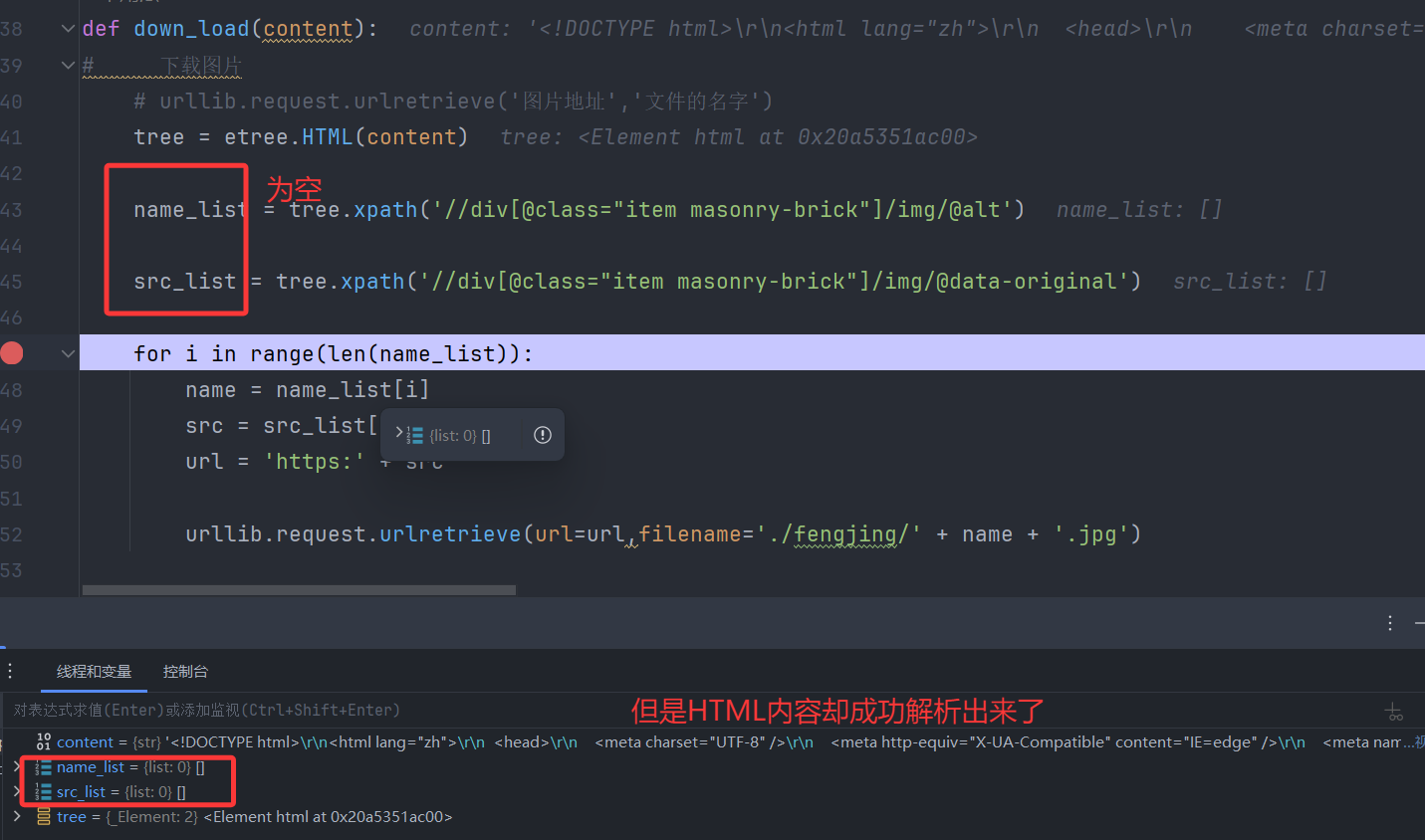
原因并不是处在xpath解析式上,而是返回的content中的HTML源码与网页的HTML源码不是同一个!
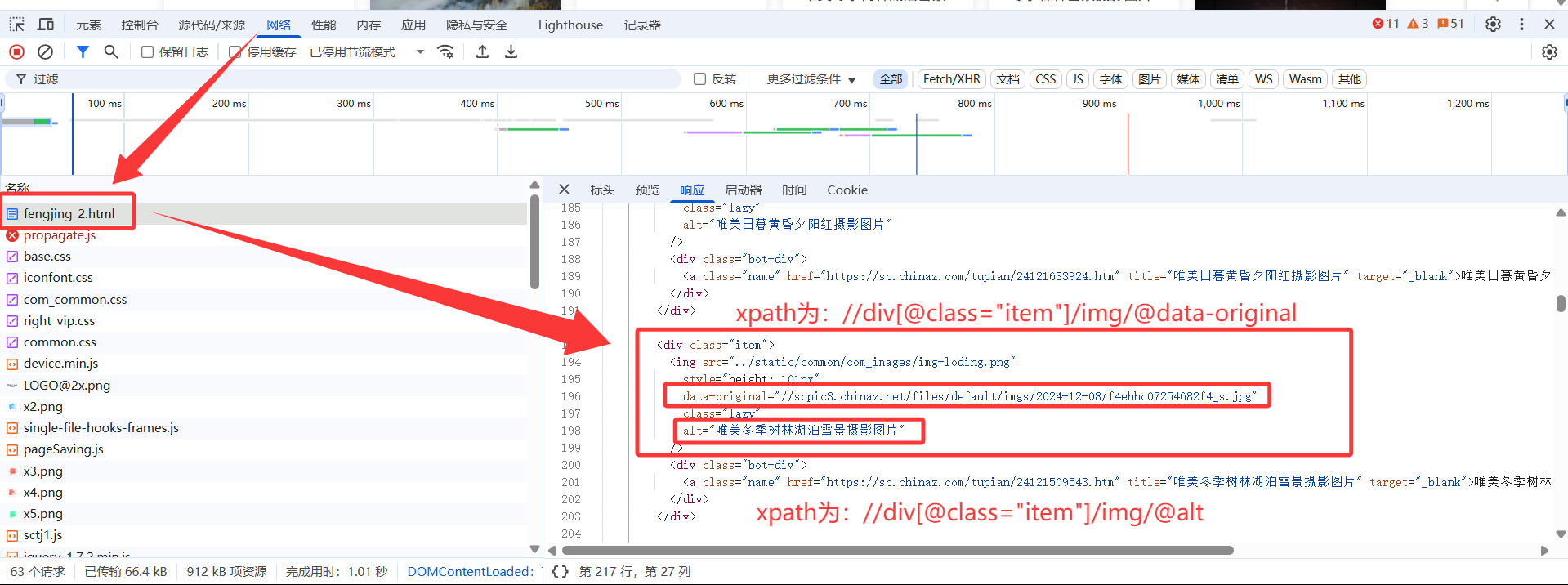
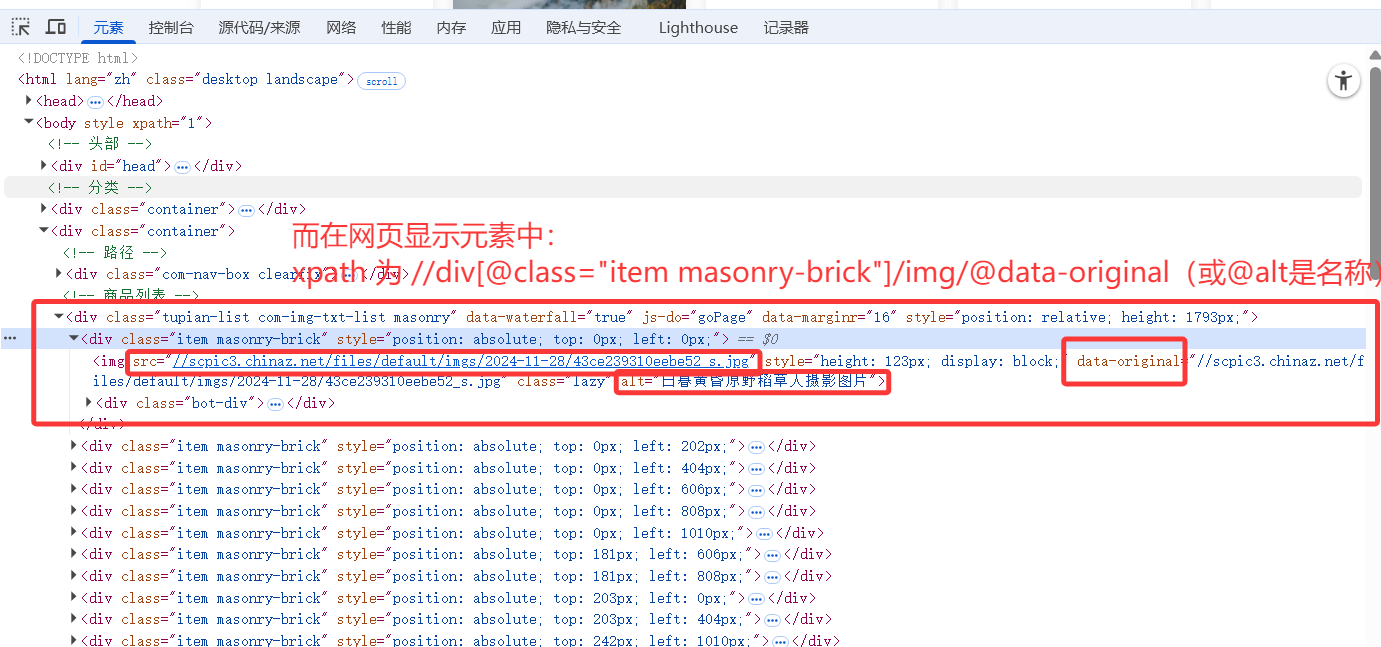
调试发现,获取的HTML版本是通过网络请求直接返回的那个
不一样的原因在于:浏览器执行了js代码,修改了类名,而爬取的网页是原始静态html,没修改类名。
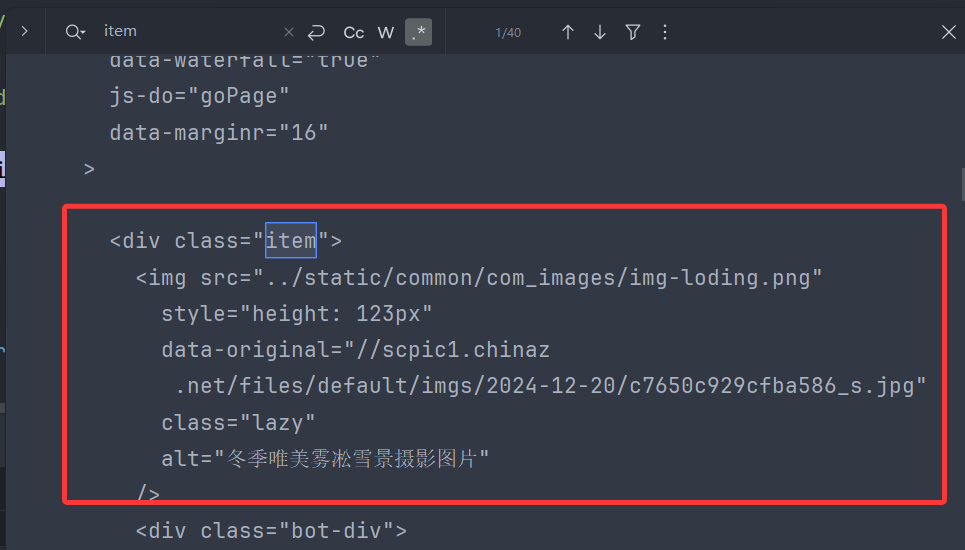
2. 图片懒加载——你所见的不一定是真实的
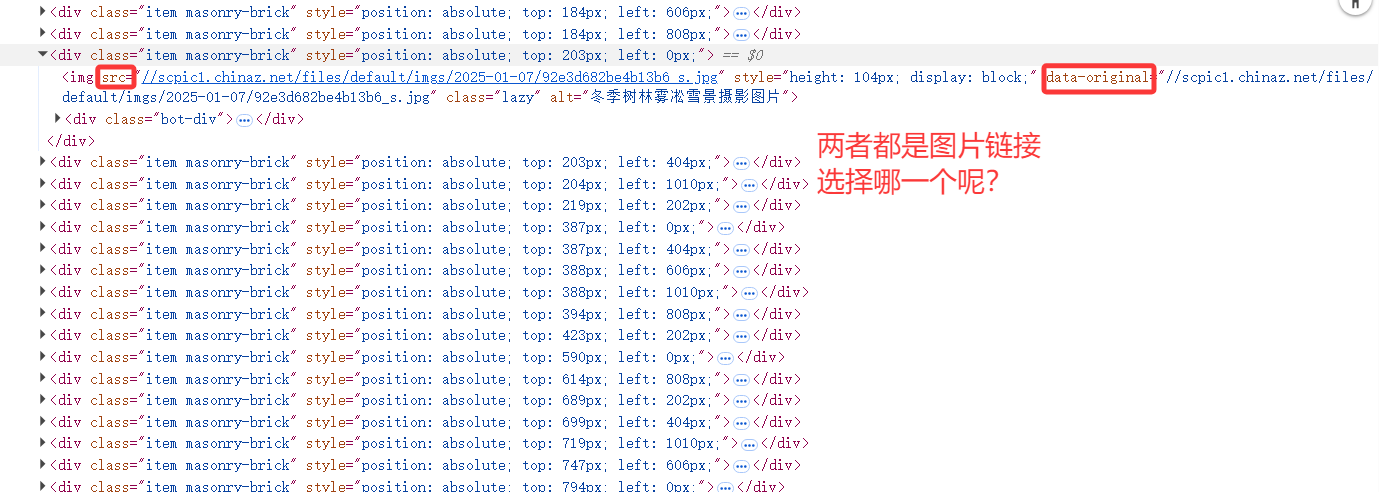
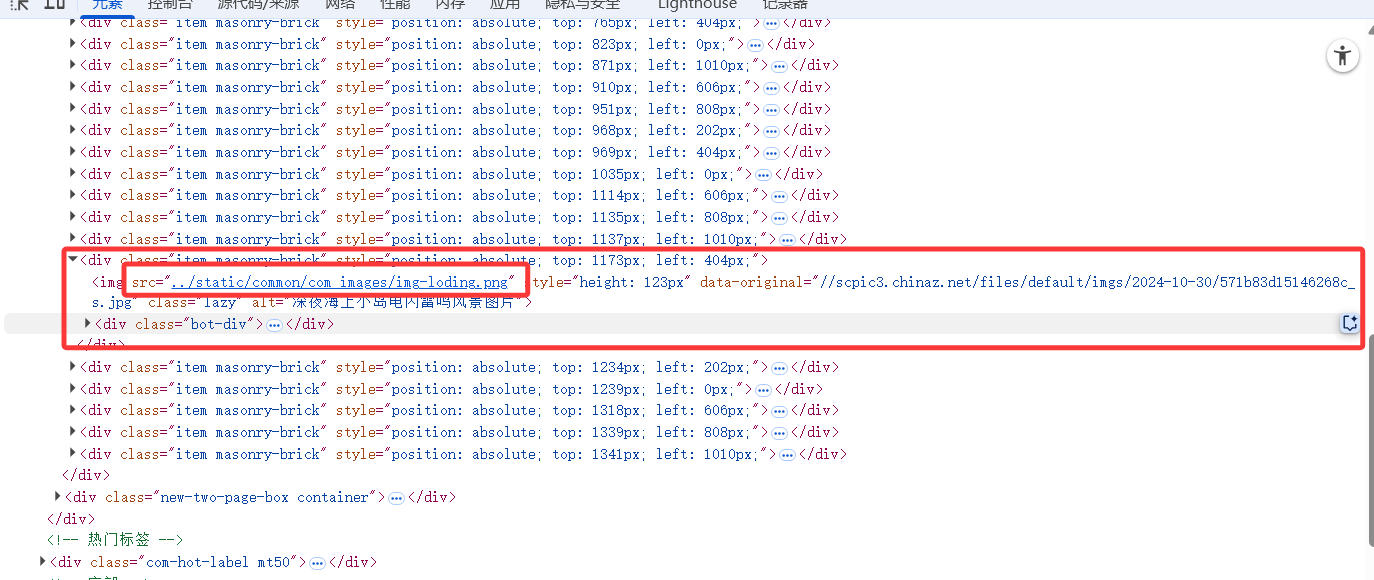
那么问题又来了,当有两个属性都是图片的链接地址,我该选择哪一个?有个小技巧是重新刷新网页——因为你有可能已经向下滑动,使得图片已被加载,刷新后,不要向下拖动,直接观察靠后的图片的链接地址,可以发现问题:图片在还没有被加载时,src属性并没有对应上图片链接(是默认图),所以在此例子中,original-data才是我们想要的
3.selenium测试时元素定位失败?
原因:本地测试时,某个元素可能确实在那个位置上,标签信息也没写错。但是在selenium打开的浏览器中,同样的元素,对应的标签名可能有细微的差异,所以需要在selenium打开浏览器后,开F12进行定位
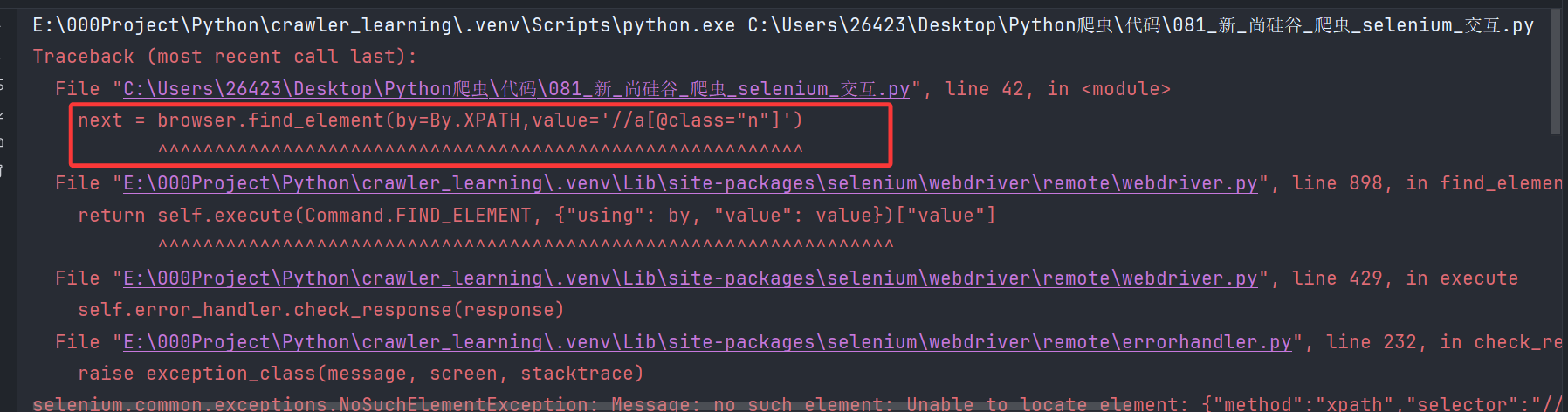
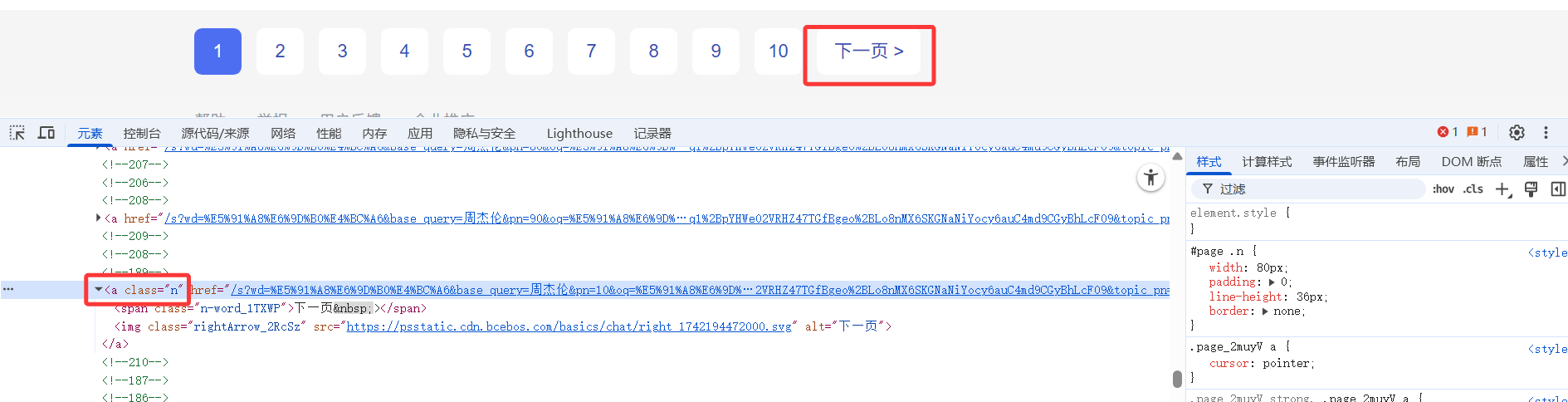
遇到问题:使用本地浏览器测试得到的、正确的xpath语句,在代码的selenium环境下却无法查询到元素!
然后,在selenium环境下的“浏览器”中F12进行元素定位:
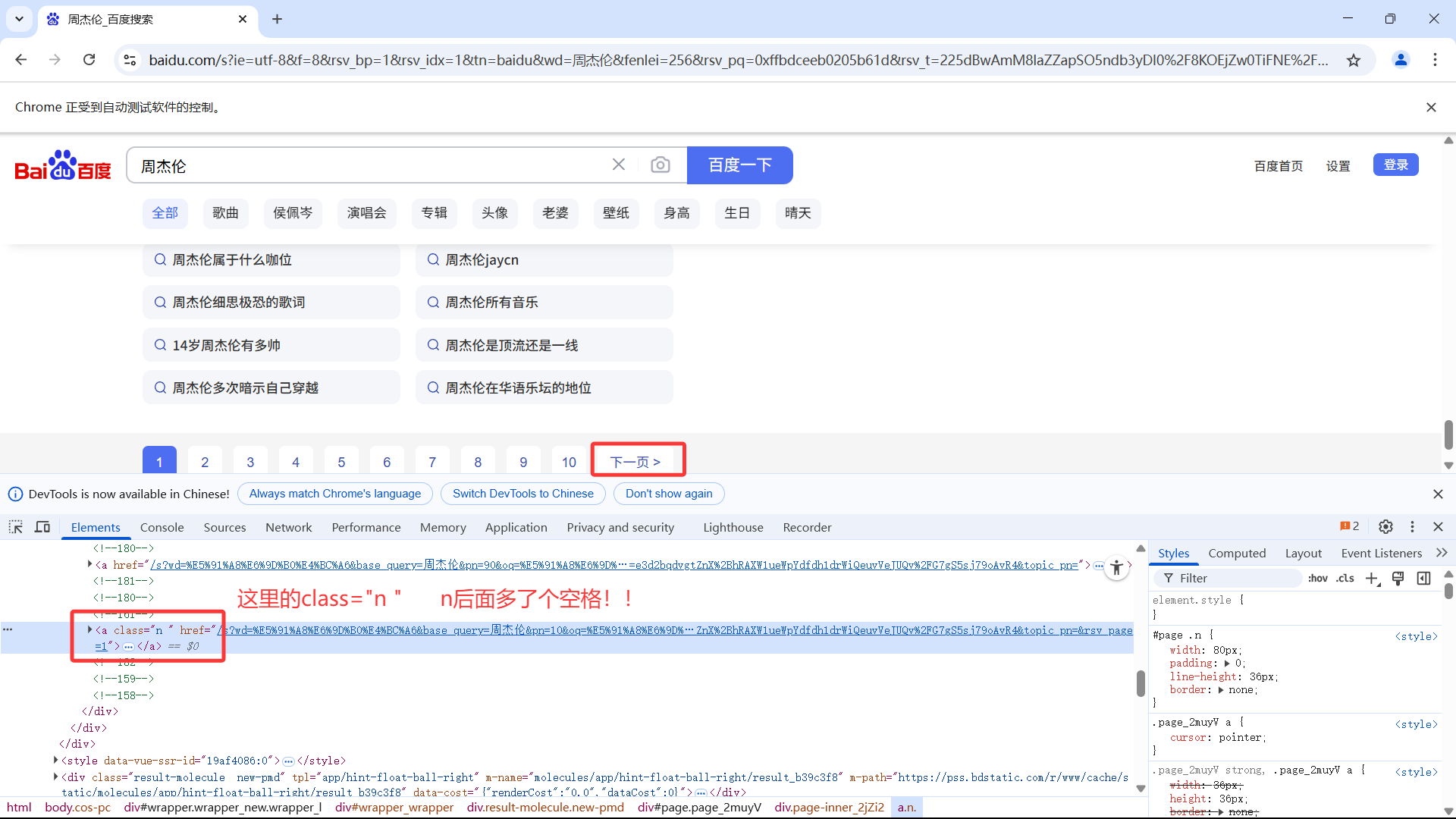
修改代码中的xpath解析式,成功定位到该元素




