
DataStructure基础——并查集
并查集
由于目录编排原因,好像并查集是图?并不是,它是一种独立的抽象的数据结构。可以看做是一棵树或森林。
并查集的定义以及算法实现参考了OI WIKI并查集以及blog提供了形象生动的例子。
同时参考了GPT所提供应用、代码。
基本介绍:
并查集(DSU),全称为Disjoint Set Union。
并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素。
顾名思义,并查集支持两种操作:
合并(Union):合并两个元素所属集合(合并对应的树)
查询(Find):查询某个元素所属集合(查询对应的树的根节点),这可以用于判断两个元素是否属于同一集合
删除、移动属于扩展的操作,需要将parent数组增加值两倍,还新增一个size[]来记录每个集合中元素个数,其大小也是两倍。
- 通常情况下并查集的标准实现只需要
find和unite就行,如需扩展功能才将数组空间变为两倍,因此也给出两种代码。
并查集的应用:
- 连通性问题
- 并查集最经典的应用之一是判断图中节点是否连通。假设你有一个无向图,需要动态地判断两个节点是否属于同一个连通块,或者在图中添加边并进行连通性判断。并查集通过“合并”和“查找”操作,能够在近乎常数时间内解决这一问题。
- 判断两个城市是否在同一条道路网络中。
- 判断两个计算机是否在同一个局域网中。
- 最小生成树
- 并查集是 Kruskal 算法的核心部分。Kruskal 算法通过对边进行排序并逐步合并节点,最终得到图的最小生成树。在这个过程中,使用并查集判断两个节点是否属于同一集合,防止产生环。
- 计算带权图的最小生成树,最小成本的通信网络布设。
- 动态连通性
- 在一些实时问题中,可能会动态地增加边或删除边。并查集可以高效地处理这种动态连通性的问题,例如:在某些社交网络中判断两个人是否处于同一网络中,或者当一条连接断开时判断网络是否仍然连通。
- 判断社交网络中两个用户是否在同一个群组。
- 判断计算机网络中两个节点是否能通信。
- 图的环形检测
- 在图的遍历过程中,环的检测是一个常见问题。利用并查集可以高效地检测图中是否有环。当你尝试合并两个已经在同一集合中的节点时,说明已经发现了一个环。
- 判断一个无向图中是否存在环。
- 判断一个任务依赖图中是否存在循环依赖。
- 分割问题
- 在图中,分割或切割的目标是将图分割成多个连通块。并查集可以帮助快速地找到哪些节点属于同一块,从而实现图的分割。
- 网络中的分区,找到某些节点之间的最大割集。
- 计算机科学中的图像分割问题。
- 动态连通性与并查集扩展
- 一些复杂的动态连通性问题,可以使用并查集的扩展版本进行处理。例如,在动态树形结构的查询和更新中,可以通过并查集进行高效操作。
- 在数据流中,快速查询和更新不同数据块之间的连接关系。
- 岛屿问题
- 给定一个二维矩阵,其中每个元素表示一个格子,格子值为
1表示陆地,0表示水域。通过并查集,可以快速求解岛屿的个数,即求连通的陆地块的个数。 - 在一个地图中,找到所有孤立的岛屿区域。
- 给定一个二维矩阵,其中每个元素表示一个格子,格子值为
- 动态查询最小生成树
- 并查集也可以用于处理某些动态修改图的问题,如在某些图的边权改变时,需要动态查询和更新最小生成树。通过与其他算法结合,保持并查集的结构可以高效更新图中的连通信息。
算法实现思路:
初始化
查询
find我们需要沿着树向上移动,直至找到根节点。
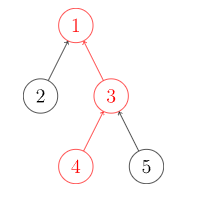
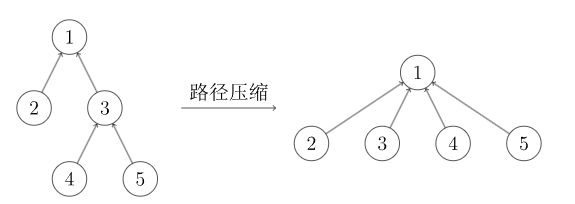
路径压缩,可以加快后续的查找速度。
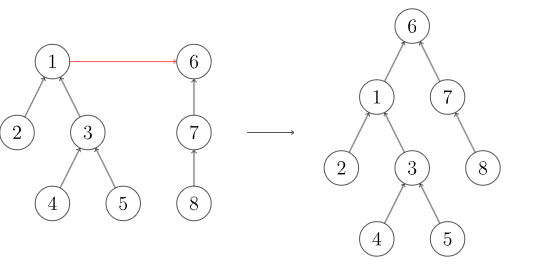
合并
要合并两棵树,我们只需要将一棵树的根节点连到另一棵树的根节点。
补充:启发式合并
合并时,选择哪棵树的根节点作为新树的根节点会影响未来操作的复杂度。我们可以将节点较少或深度较小的树连到另一棵,以免发生退化。
删除
erase要删除一个叶子节点,我们可以将其父亲设为自己。为了保证要删除的元素都是叶子,我们可以预先为每个节点制作副本,并将其副本作为父亲。
实际上,这里的删除操作,只是将该元素的parent指向他自己。
- 该操作的效果是 “断开” 元素
x与它原来集合的联系,使x成为一个新的单元素集合,但并没有真正删除x本身,也没有改变其它集合的结构。 这意味着,
x会从原集合中“移除”,但其索引仍然存在于数据结构中。换句话说,erase操作并没有修改parent数组的大小,也没有真正从数据结构中“删除”元素,只是把x从原来的集合中分离出来。为什么?
这样的设计通常用于 懒惰删除(lazy deletion)或者当需要在集合中分割元素时。这种方式避免了删除元素时可能出现的性能开销,特别是在处理大数据结构时。
另外,
erase操作本身可能用于某些特定场景,比如让元素独立出来,变成一个单独的集合,供后续操作使用。
进一步改进:
- 如果需要完全删除某个元素并从集合中移除,可以考虑设计一个额外的机制来真正删除元素,可能会涉及到管理集合中实际元素的列表或数组。
- 该操作的效果是 “断开” 元素
移动
与删除类似,通过以副本作为父亲,保证要移动的元素都是叶子。
带权并查集:
我们还可以在并查集的边上定义某种权值、以及这种权值在路径压缩时产生的运算,从而解决更多的问题。
比如对于经典的「NOI2001」食物链,我们可以在边权上维护模 3 意义下的加法群。
标准并查集实现
DSUDemo
感谢GPT
1 | package com.yukinoshita.dataStructure.dsu; |
扩展并查集实现
ExtendedDSUDemo
1 | package com.yukinoshita.dataStructure.extendedDsu; |




